2.4 Content Management in Green OA
One of the most important elements of Green OA development is selecting the software system that best satisfies the needs of the institution. These needs will be driven by each institution’s content policies and by the various administrative and technical procedures required to implement those policies. Open Society Institute developed a guide for selecting institutional digital repository (IDR) software46 against some framed parameters. This guide includes the IDR software that satisfies three criteria:
- Available via an Open Source license — that is, they are available for free and can be freely modified, upgraded, and redistributed;
- Comply with the latest version of the Open Archives Initiative metadata harvesting protocols —this OAI compliance helps ensure that each implementation can participate in a global network of interoperable research repositories; and
- Currently released and publicly available — several new systems are currently being developed.
The next important task in Green OA development is building content management workflow on the basis of organizational "Communities" —natural sub-units of an institution that have distinctive information management needs. Communities are defined to be the schools, departments, labs, and centers of the institute. Each community can adapt the system to meet its particular needs and manage the submission process itself. Communities can be divided into sub-communities, which can be further sub-divided and Collections are part of a community or sub-community.Items are the actual resources that are uploaded into the IDR. Each item may belong to one collection. Each item contains bit streams that are the computer files which make up the IDR resource.
2.4.1 Selection of Software
A total of seven repository software has been identified from the open source domain that satisfies the above criteria as framed by Open Society Institute. These are:
ARNO
The ARNO project—Academic Research in the Netherlands Online—has developed software to support the implementation of institutional repositories and link them to distributed repositories worldwide (as well as to the Dutch national information infrastructure). The project is funded by IWI (Dutch acronym for: Innovation in Scientific Information Supply). Project participants are the University of Amsterdam, Tilburg University and the University of Twente. The ARNO system was released for public use in December 2003. It is designed to provide a flexible tool for creating, managing, and exposing OAI-compliant archives and repositories. The system supports the centralized creation and administration of repository content, as well as end-user submission. While ARNO offers considerable flexibility as a content management tool, it does not provide a self-contained, “off-the-shelf” institutional repository system. To be able to offer these services ARNO implementers need to deploy other, third party software (e.g. iPort, i-Tor).
CDSWare
CDSWare is maintained and made publicly available by CERN and supports electronic preprint servers, online library catalogs, and other web-based document depository systems. CERN uses CDSware to manage over 450 collections of data, comprising over 620,000 bibliographic records and 250,000 full-text documents, including preprints, journal articles, books, and photographs. CDSware was built to handle very large repositories holding disparate types of materials, including multimedia content catalogs, museum object descriptions, confidential and public sets of documents, etc. Each release is tested live under the rigors of the CERN environment before being publicly released.
DSpace
DSpace is designed by MIT in collaboration with the Hewlett-Packard Company between March 2000 and November 2002. Version 1.1.1 of the software was released in August 2003. The system is running as a production service at MIT, and a federation comprising large research institutions is in development for adopters worldwide. DSpace architecture supports the participation of the schools, departments, research centers, and other units typical of a large research institution. As the requirements of these communities might vary, DSpace allows the workflow and other policy-related aspects of the system be customized to serve the content, authorization, and intellectual property issues of each. Supporting this type of distributed content administration, coupled with integrated tools to support digital preservation planning, makes DSpace well suited to the realities of managing a repository in a large institutional setting.
Eprints
The University of Southampton developed the Eprints software for managing large institute oriented digital archive for scholarly objects. The first version of the system was publicly released in late 2000. The project was originally sponsored by CogPrints, but is now supported by JISC as part of the Open Citation Project and by NSF. Eprints worldwide installed base affords an extensive support network for new implementations. The size of the installed base for Eprints suggests that an institution can get it up and running relatively quickly and with a minimum of technical expertise.
Fedora
The Fedora digital object repository management system is based on the Flexible Extensible Digital Object and Repository Architecture (Fedora). The system is designed to be a foundation upon which full-featured institutional repositories and other interoperable web-based digital libraries can be built. Jointly developed by the University of Virginia and Cornell University, the system implements the Fedora architecture, adding utilities that facilitate repository management. The current version of the software provides a repository that can handle one million objects efficiently. The system’s interface comprises three web-based services: A management API that defines an interface for administering the repository, including operations necessary for clients to create and maintain digital objects; An access API that facilitates the discovery and dissemination of objects in the repository; and A streamlined version of the access system implemented as an HTTP-enabled web service.
i-TOR
i-Tor—Tools and technologies for Open Repositories—was developed by the Innovative Technology-Applied (IT-A) section of Netherlands Institute for Scientific Information Services (Dutch acronym: NIWI). NIWI calls i-TOR “a web technology by which various types of information can be presented through a web interface,” irrespective of where the data is stored or the format in which it is stored. i-Tor aims to implement a “data independent” repository, where the content and the user-interface function as two independent parts of the system. In essence, i-Tor acts as both an OAI service provider, able to harvest OAI compatible repositories and other databases, and an OAI data provider.
MyCoRe
MyCoRe grew out of the MILESS Project of the University of Essen. The MyCoRe system is now being developed by a consortium of universities to provide a core bundle of software tools to support digital libraries and archiving solutions (or Content Repositories, thus “CoRe”). The bundle is designed to be configurable and adaptable to local requirements (hence, the “My”), without the need for local programming efforts. The core contains all the functionality that would be required in a repository implementation, including distributed search over geographically dispersed repositories, OAI functionality, audio/video streaming support, file management, online metadata editors etc. These seven open source IDR software may be compared by following the framework developed by Open Society Institute54. The basic parameters are:
- Standard system features
- Hardware, Companion software and Database
- Client, Staff requirements and Installation base
- Repository administration: Installation and Update
- User management
- Content submission management
- Content management
- User interface and Search features
UNESCO recently (2014) released an institutional repository software comparison55, and you may further like to study the same. Each of these basic parameters is again divided into number of factors. Let’s examine content management features of Green OA software under three most important issues related with OA content management.
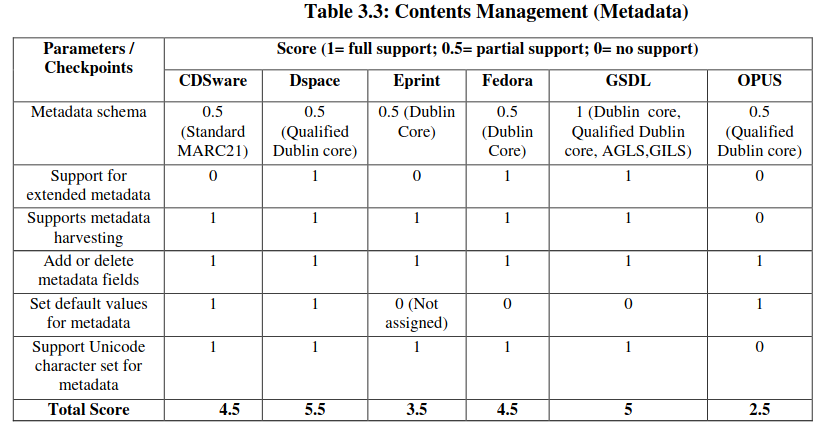
Content Management: Metadata
OSI identified six factors under this group:
- Metadata schema
- Support for extended metadata
- Metadata harvesting
- Addition/Deletion of metadata fields
- Set default values for metadata
- Support Unicode character set for metadata
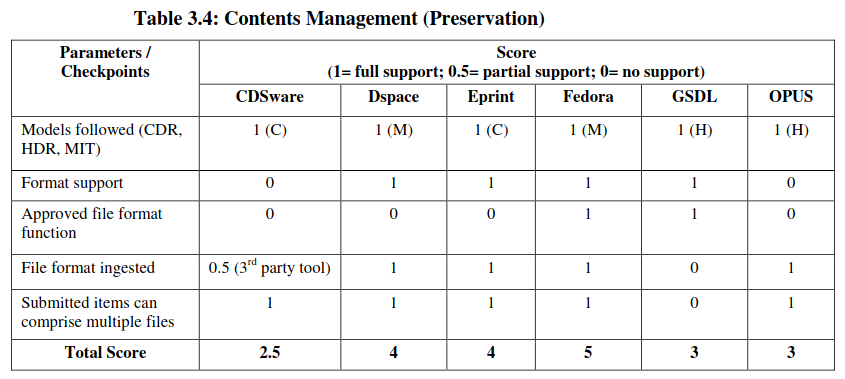
Content Management: Preservation
Preservation is another important issue of OA content management. It is also based on five parameters as prescribed by OSI guide. Generally Green OA software follows three models of OA content preservation namely California Digital Library (CDL), IDR of MIT library (MIT) and Harvard Digital Repository Services (HDR). The parameters are:
- Models followed (CDR, HDR, and MIT)
- Format support
- Approved file format function
- File format ingested
- Submitted items can comprise multiple files
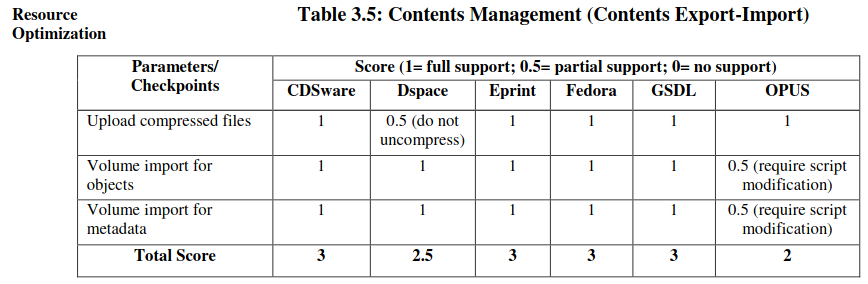
Content Management: Content Export- Import
This particular section has been examined on the basis of the three points mentioned below:
- Upload compressed files
- Volume import for objects
- Volume import for metadata
2.4.2 Content Management Workflow
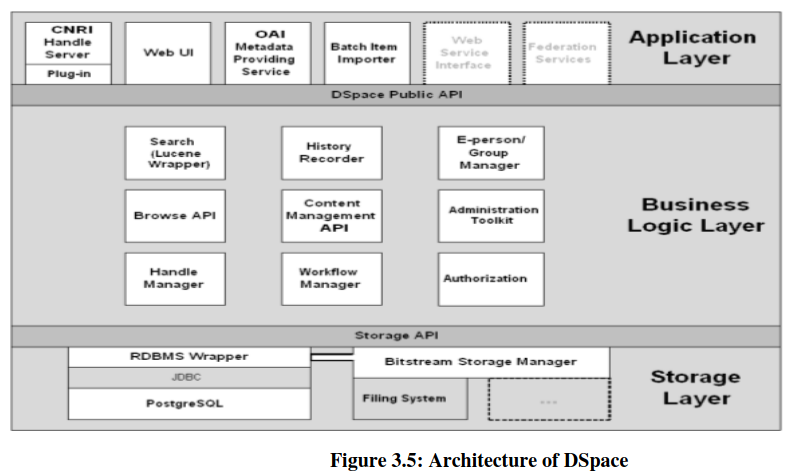
Most of the above mentioned Green OA software follows OAIS reference model and organizes OA contents into three layers, each of which consists of a number of components. For example, DSpace is based on three layers as follows (Figure 3.5):
- Storage layer: responsible for physical storage of metadata and content;
- Business logic layer: deals with managing the content of the archive, users of the archive (e-people), authorization, and workflow; and
- Application layer: containing components that communicate with the networked world outside of the individual repository software installation, for example the Web user interface and the modules for metadata harvesting service.
Metadata management
Most of the Green OA software use qualified Dublin Core metadata standard for describing items intellectually (specifically, the Libraries Working Group Application Profile, see unit 1 of Module 4 for details). Only three fields are mandatory: title, language, and submission date. All other fields are optional. Content management deal with/come across metadata in the following modules:
- Administration modules: Dublin core registry, administrative metadata- default values, mail alert to subscribers;
- Submission modules: descriptive metadata;
- Harvesting – OAI-PMH using the DC elements (unqualified); and
- Search result display: brief and full metadata.
Workflow management
After installation and initial configuration of software, a series of related questions are required to be solved.
- Who is allowed to deposit items?
- What type of items will they deposit?
- Who else needs to review, enhance, or approve the submission?
- To what collections can they deposit material?
- Who can see the items once deposited?
All of these issues are part of content management system- contributors, end users and support staff, and are then modeled in a workflow for each collection to enforce their decisions. Generally OA content management starts with defining e-people who have roles in the workflow of a particular Community in the context of a given collection. Individuals from the Community are registered with OA system, and then assigned to appropriate roles. This workflow can be represented schematically as in Figure 3.6.
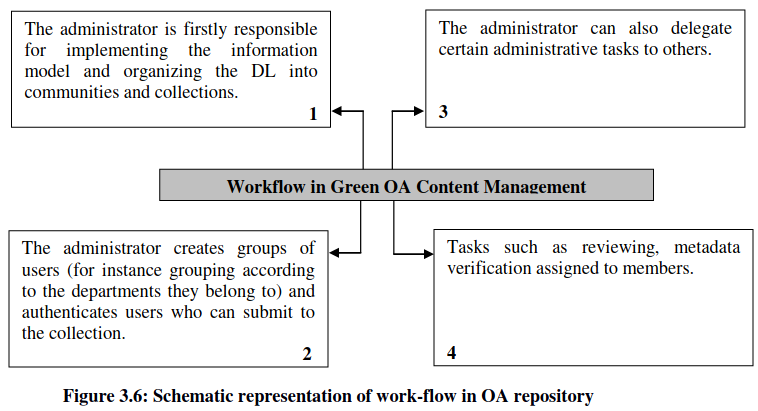
- Users can register themselves as members. Members can subscribe to entire collections or sub-collections depending on their interests. Mail alerts are sent to the members of each collection whenever a resource is added to that collection.
- Members authenticated by administrator as ‘submitters’ can submit resources to the collection.
- The submitters are required to furnish metadata, basically Dublin Coredata, for the resource they are submitting to the IDR. Resources with amultiple files (such as website) can also be submitted.
- The submitters are required to agree with the terms and condition oflicensing set forth by the OA system before their submission can be passedon for review process. License information for every resource is stored.
- Content management supports many popular data formats and has theprovision for registering new bit stream formats.
Content Identifier
One goal of OA content management is to ensure persistent access to resources so that it is possible to find and retrieve deposited items far into the future. In particular, it is considered crucial that citations to archived material, whether found in printed articles or online, remain valid for long periods. To achieve this goal, DSpace implemented CNRI handles as the persistent identifier associated with each item. The Handle System covers assignment, management, and resolution of these persistent identifiers (or "handles"). Although CNRI has not registered with the IETF for an official namespace, handles are compliant with the IETF's Uniform Resource Name (URN) specification.
User Interface
User interfaces of web-scale repository software generally include different interfaces like:
- One for submitters and others involved in the submission process;
- One for end-users looking for information; and
- One for system administrators.
The end-user or public interface supports search and retrieval of items by browsing or searching the metadata. Once an item is located in the system, retrieval is accomplished by clicking a link that causes the archived material to be downloaded to the user's web browser.
Search and Retrieval
The end user can browse, search and access the collections using the hierarchies and also the alphabetic bar menu. Almost all open source OA repository software use open source Text Retrieval Engines for content retrieval. OA content management system is known to users for its features related with OA contents retrieval.
Interoperability
As per IEEE, interoperability is the ability of two or more systems or components to exchange information and to use the information that has been exchanged. An OA content management system should support all interoperability areas as identified by COAR (Confederation of Open Access Repositories):
- Metadata level interoperability: It refers to integration of metadata from different open access resources into a single-window service on the basis of metadata harvesting protocols and standards like OAI/PMH.
- Content level interoperability: This refers to the facilities of multiple-deposit process where author submits document in one place and automatically contents transfer from one system to another.
- Network level interoperability: This supports development of national and regional repository networks on the basis of metadata harvesting.
- Statistics and usage data level interoperability: It supports aggregation and exchange of usage information from different repositories and information systems (like CiteSeer).
- Identifier level interoperability: It refers consistency in identification and naming of authors, items, location of items, institutions, funding agencies, grants etc in organizing open access resources.
- Object level interoperability: This refers exchange of compound digital objects on the basis of standards for exchange of web resource aggregations.
- Semantic level of interoperability: This refers to meaningful exchange of data at machine-level. (You may refer to Unit 2 of Module 4 for details of interoperability issues related with OA content management).