3.7 Designing Harvesting Framework
Design and development of harvesting framework requires an array of steps, strategies and planning. The three major components of such a framework design are – i) development of software architecture; ii) selection, installation and configuration of harvesting tool; and iii) selection of repositories and collection of essential attributes for harvesting (title, resource URL, base URL, mail id of administrator etc.). The prototype harvesting framework may be developed by you at your library based on open source software and open standards. It uses Linux as operating system, Apache as Web server, MySQL as RDBMS i.e. LAMP architecture as base, and PKP version 2.X as harvesting tool.

The requirements of PKP harvester are as follows:
- PHP >= 4.2.x (including PHP 5.x); Microsoft IIS requires PHP 5.xMySQL >= 3.23.23 (including MySQL 4.x/5.x)
- Apache >= 1.3.2x or >= 2.0.4x or 2.0.5x /Microsoft IIS 5.x or 6.x
- Operating system: Any OS that supports the above software, including Linux, BSD, Solaris, Mac OS X, Windows (preferably NT based Windows flavors)
As a whole, the use of open source software in developing domain specific harvesting system depends on a structured methodology. The steps related with the creation of the harvesting framework may be divided into three major groups (Mukhopadhyay, 2010).
Group I: LAMP related activities
PKP harvester 2.X is based on AMP architecture. Naturally, you have to install Apache, MySQL and PHP prior to installing PKP harvester. Although there is no hard and fast rule, the installation sequence of this manual follows the order below: Apache (The Apache httpd server is a powerful, flexible, HTTP/1.1 compliant open source Web server)
- Installation of Apache;
- Testing of Apache; and
- Apache Configuration and Control.
PHP (PHP is an open source server side scripting language)
- Installation of PHP
- Configuration of PHP
MySQL (MySQL, the most popular Open Source SQL database is developed, distributed and supported by MySQL AB)
- Installation of MySQL
- Initialization of MySQL Server
- Creation of database, user and manage permission
Testing of AMP Links through Scripts
- Testing PHP-Apache Link
- Testing PHP-MySQL Link
Group II: Harvester related activities
Selection - The first task is to select appropriate harvesting software. A preliminary study identifies a total of four open source (as a library professional you already know the advantages of using open source software) harvesting software on the basis of their user bases. The final choice of software may be based on the selection framework given in the table below. The framework is based on six major parameters – Platform of OS; Architecture of harvesting software; Protocol support; Harvesting processes; Administration of harvesting processes; and Retrieval features.
Installation - This activity includes two major tasks – i) installation of PKP harvester and ii) configuration of PKP harvester. The installation process of PKP harvester is quite straight forward. It requires two sets of information – a) login name and password for the administrator and b) database details (name of the Mysql database, user of database and password of the database user). The configuration processes are divided into three groups – a) site management (configuration of site specific details, language, crosswalk, plug-ins and reading tools); b) Archives (creation of archives, managing created archives); and c) other administrative functions (layout, customization etc.).
Group III: Repository related activities
The most important task of the administrator is to setup archive(s) for metadata harvesting. You can start with a selective numbers of OAI/PMH compatible open access repositories. The intrinsic attributes of these repositories are given in Table 3.7.
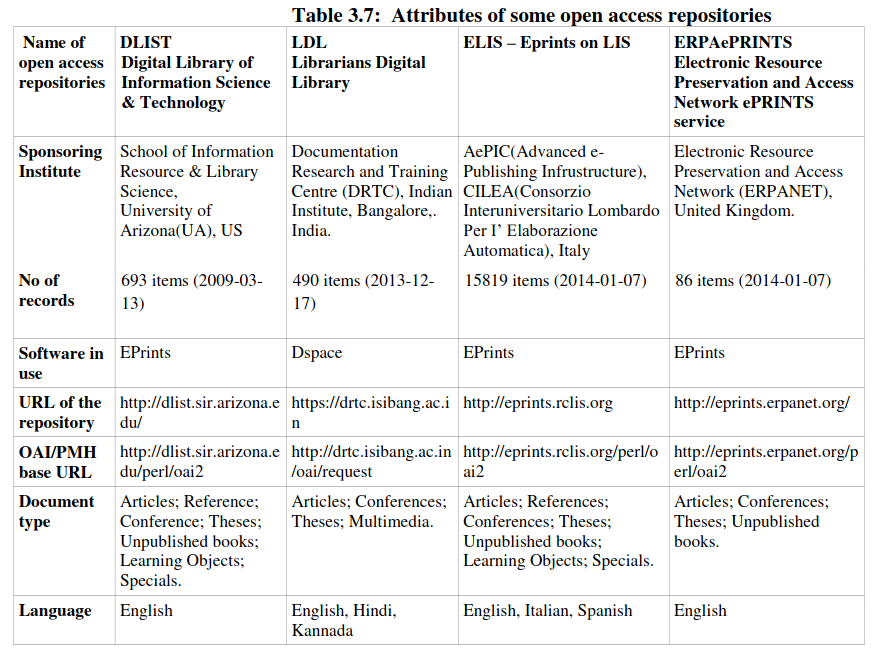
Let us say we are going to develop a harvesting service for above-listed repositories in library and information science. The BASE URL or OAI/PMH URL we may collect from OpenDOAR. Registry of Open Access Repositories75 lists around 15 LIS specific repositories which allow us tosearch & list open access repositories by subject, country and content type. After selecting suitable repositories (you want to fetch from), give OAI-PMH base URL and fetch respective repository. To fetch a repository, there are few steps relating to Open Harvesting Software which is based on PKP software.
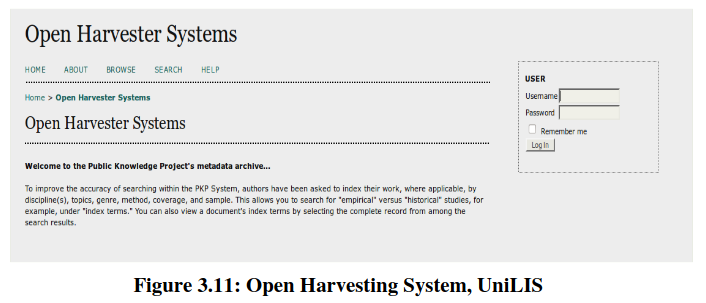
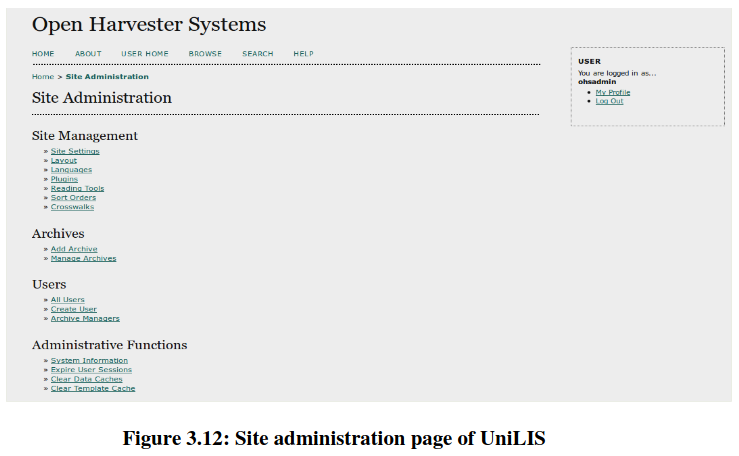
It will facilitate you to access administrative home page of UniLIS (example in Figure 3.11) from where you can add archive or manage your archive. You can also do site management and administrative functionalities from this home page (Fig. 3.12).
Let’s start with add archive. Our main motto is to create a domain specific institutional repository. After clicking on “Add Archive” link, you will get this interface (Figure 3.13).
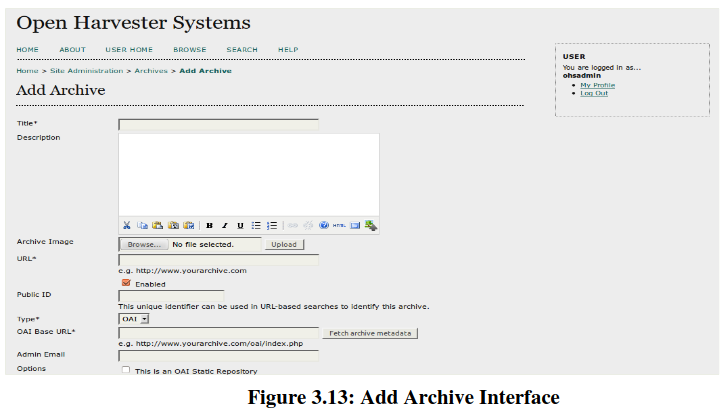
Here, you have to fill required fields to fetch a repository. The basic fields are:
- Name of open access repositories;
- Sponsoring Institute ;
- No of records;
- Software in use ;
- URL of the repository;
- OAI/PMH base URL ;
- Document type; and
- Language
On the basis of these given data of a particular repository, harvester will fetch data in its own archive. Figure 3.4 shows how it looks like after fetching data from repository. For example we fetched E-LIS and QUT ePrints repositories in UniLIS due to its good number of valuable records.

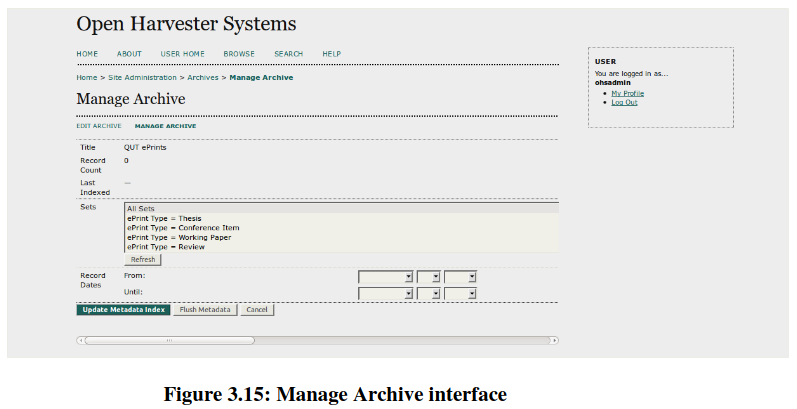
From this interface we can edit, manage or even delete this repository (Figure 3.15). Let’s think positive and manage this repository by clicking on manage link. At the moment, you are clicking on manage link by which you will get this interface where you have the provision to “update metadata index” for “All sets”. It will take time depending on the speed of the network (a few minutes to a few hours) in order to fetch full repository. It is possible to harvest in selective order like “by collection”, “by date range” etc.
After updating, the harvester will show the listed repositories including number of records that are fetched in its archive (Figure 3.16). Repositories are now browsable and searchable by end-users. One can browse a particular repository by clicking on it.

There is also search option from where you can search by repository, contributor, coverage, date etc. And from here any one can see metadata related information centrally by clicking on “View Record” (archive information) and can access it in global platform by clicking on “View Original” (from repository information) (Figure 3.17).

So far harvesting works well with Green OA or OARs that include pre/post print versions of journal articles, theses, reports, learning objects, slide presentations etc. It supports localized searching of metadata elements in two modes – simple and advance. Users can limit search in a single repository or a group of repositories (by default a given search session includes all the available repositories). Search can be filtered by DC metadata elements like title, author, date range, language etc. The latest version of PKP can harvest metadata from DCMES (Simple DC metadata), MARC 21 Bibliographic Format and ETD-MS (metadata for electronic theses and dissertations). Harvesting is a modest beginning of a new era of localized search services that harvest metadata from different OAI/PMH compatible open access resources such as, open access journals, open access repositories and open access ETDs etc. Even we can use one single search interface for different services of an institution. In next section, we will explore the integration between these two different services in a single local search interface. Many major OA services like BASE search engine, OAIster etc. are developed on the basis of harvesting technology.