2.5 Application of Interoperability: Metadata Harvesting
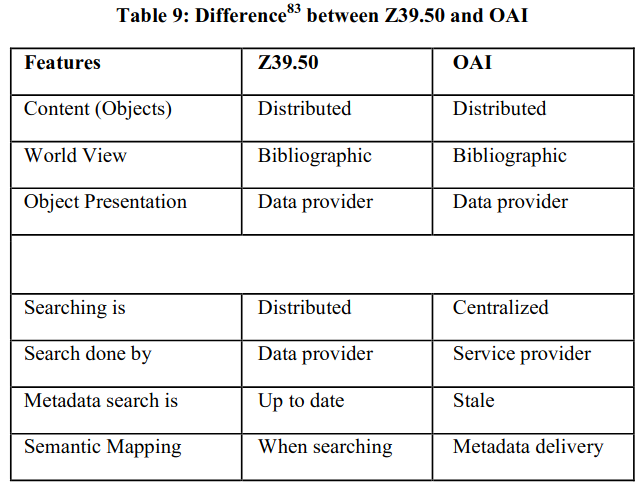
The Open Archives Initiative Metadata Harvesting Protocol (OAI/PMH) supports interoperability and sharing of metadata across an array of open access repositories. The creation of large repositories by using OAI/PMH protocol is advantageous to bring together scholarly information bearing objects and cultural resources. However, the mixing of metadata from a variety of institutions and communities poses difficulties for discovery and interoperability. OAI/PMH differs from Z 39.50 in many aspects as interoperability standard (Table 9).
Open source OAI harvesting tools provide opportunities to make the difficult job an easy one. There is an array of open source harvester software (compatible with OAI/PMH V.2) such as
- Arc (Old Dominion University, URL: http://arc.cs.odu.edu/)
- my.OAI (FS Consulting, Inc., URL: http://www.myoai.com/)
- OAIster (University of Michigan, URL: http://www.oaister.org/)
- PKP Harvester (Public Knowledge Project, URL: http://pkp.sfu.ca/harvester2/)
PKP (Public Knowledge Project) harvester developed by University of British Columbia has already been proved as an excellent metadata harvesting and presentation tool. This multi-platform Web-based tool extracts data and presents it in a coherent manner. It employs an intuitive user interface to organize data (see Evaluation of Open Source Spidering Tools84). PKP harvester (presently in version 2.3.x) is a platform independent A (Apache) - M (MySQL) –P (PHP) based application software. The AMP requirements are as follows:
- PHP >= 4.2.x (including PHP 5.x);
- MySQL >= 3.23.23 (including MySQL 4.x/5.x)
- Apache >= 2.0.4x or 2.0.5x; and
- Operating system: Any OS that supports the above software, including Linux, BSD, Solaris, Mac OS X, Windows (preferably NT based Windows flavors).
Design and development of harvesting framework by using PKP requires an array of steps, strategies and planning. The three major components of such a framework design are:
i) Development of software architecture (Installation of Apache, MySQL and PHP and linking these tools for seamless interaction);
ii) Selection, installation and configuration of harvesting tool (Selection of PKP harvester and configuration settings like proxy server settings, homepage customizing etc); and
iii) Selection of repositories and collection of essential attributes for harvesting
The data elements like title, resource URL, OAI base URL, mail id of repository administrator are essential to start harvesting a selected repository. OpenDOAR is an excellent source to collect all the required data related to OAI/PMH compliant open access repositories such as title of repository, repository URL, and OAI base URL. After successful harvesting, PKP harvester gathers metadata from selected repositories through OAI/PMH protocol and allows users to browse or search (both simple and advanced search interfaces are available) all metadata elements collected from different selected repositories through a single-window search interface and thereby helps users to get rid of drudgery of moving from one repository to another repository. OAI/PMH supports harvesting not only the metadata formatted in DCMES (Dublin Core Metadata Elements Set) but also rich metadata sets like ETD-MS, Qualified DCMES etc. The interoperability initiatives like KE-USG, NEEO, SURE, PIRUS, OA-Statistik etc harvesting usage data through OAI/PMH. The exclusive open access search engine BASE (base-search.net) and services like OAISter depends on OAI/PMH for collecting metadata from different resources. Open source repository management software like Dspace, Eprint archive, Greenstone are fully compatible with OAI/PMH version 2.0 and these softwares can act as data providers as well as service providers.