3.3 Retrieval Of Open Contents: A State-Of-The Art Report
Users generally perform information retrieval tasks in three ways. These are searching, browsing and a combination of searching and browsing. Searching is a structured retrieval process. It intends to find out the resources that would match with the query terms by using available retrieval techniques. On the other hand, browsing is finding and selecting resources by skimming and scanning. Browsing did not receive much attention in the regime of online IR (dominated by commercial database vendors and database aggregators) because of high connection charges. But it started getting attention with the advent of CDROM based IR and gained popularity in Web based IR. Open access retrieval systems are essentially Web-enabled IR and support all these three retrieval tasks. The role of these three basic retrieval tasks may be understood in a better way through an analogy. Koll (2000) proposed a structured analogy between information retrieval and finding needle in haystack (Figure 27). In this proposition, needle stands for information resources and haystack represents IR system. Koll enumerated a total of twelve possibilities, which can be matched with three retrieval methods i.e. searching, browsing and combination of searching and browsing.

3.3.1 Organization of Open Contents
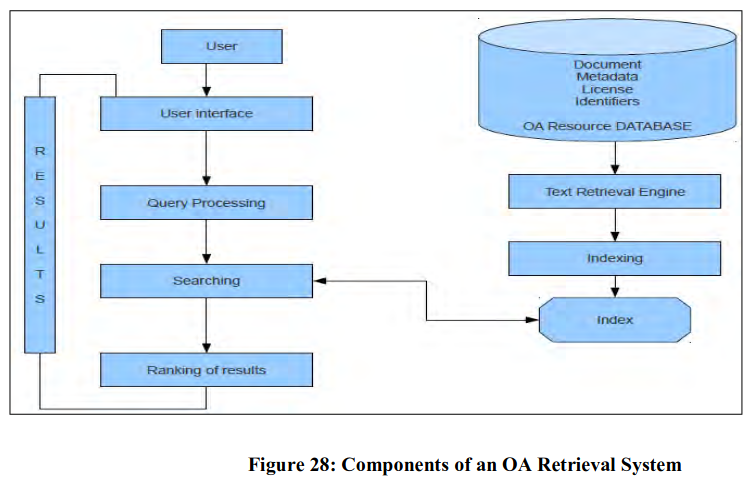
Information Representation and Retrieval (IRR) activities entered into digital age with the advent of ICT in general and the Web in particular. ICT influenced the design and development of four major components of any IR systems (any type or size) including OA retrieval. These components are database, search process, language of IRR and user interface. OA retrieval system is essentially based on database and language of IRR at the core. The search processes support matching of search queries and documents on the basis of metadata and contents of documents through an intuitive user interface.
Database
Databases form the core of Web-enabled OA retrieval system. Bibliographic database technologies exclusively deal with textual objects. Traditional bibliographic databases (online and CDROM databases) include two parts. The first part is sequential file (field-record-database) and the second part is inverted file (indexes to sequential file). On the other hand, Web-enabled IR systems also contain two parts but the sequential files are generally made of field-less information entity (i.e. full-text resources in Web page (HTML, XML) format, PDF format etc).
Search process
Database determines what can be retrieved from the OA retrieval system, whereas search mechanism determines how open access resources stored in databases can be retrieved. It provides search algorithms and procedures for retrieving open contents. Generally search mechanism of an IR system provides two sets of retrieval techniques – basic retrieval techniques (Boolean, relational and positional search operators) and advance techniques (weighted searching, fuzzy searching, term boosting, soundex search, relevance ranking etc.). Text retrieval engine plays a pivotal role here in OA retrieval.
Language of IRR
Search mechanism determines what retrieval techniques will be available to searchers for retrieving open contents, whereas language of IRR, to a great extent, determines the flexibility in information representation (metadata encoding and content description by library professional) and query representation (query formulation by searcher). Language in IRR may be grouped as natural language and controlled vocabulary (classification schemes, subject headings list and thesauri). The debate about natural language vs. controlled vocabulary is an ongoing event in IRR for many years.
User interface
It is a layer of interaction between users and IRR activities in an OA retrieval system. The utility of user interface depends on mode of interaction, display features, online help, provision of feedback, availability of statistics, web 2.0 supports to ensure participation and collaboration, RSS feeds etc. It is considered as the human dimension of IRR. The components of an OA retrieval system and their relationships may be illustrated as below (Figure28)
3.3.2 Retrieving Open Contents: Problems and Prospects
The toll based scholarly communication process limits, rather than expands the wide availability and global sharing of research resources. In such a research communication process, research publications are also obliterating their institutional origins. Exorbitant increase of journals prices and resultant subscription cancellations is affecting readership considerably. Libraries and academic communities in developing countries are worst affected. In the age of print publication, open access was physically, economically and technically impossible. But thanks to the distributed information system in general and Web in particular, OA is an emerging reality for providing viable alternative to toll-based system. OA movement promotes availability of scholarly communications in public domain through digital publishing system and thereby offers an unprecedented public good: the free online availability of peer-reviewed scientific and scholarly digital resources. The obvious advantages of OA are the widespread sharing of knowledge and the acceleration of research. OA repositories and OA journals are both practical and lawful. The emergence of OA services around the world are proving that OA can do much better than traditional subscription-based journals in their cost-effectiveness and service to science and scholarship. Moreover, OA retrieval systems are adding values in services through personalized alert services, federated search for distributed open access repositories, e-SDI service notifying a user the availability of new open contents, ontology-driven retrieval, usage data and statistics, citation linking, aggregation of OA resources by multiple logical approaches (discipline-wise, country-wise, institutional group-wise etc). But, at the same time, organization of OA resources involves some serious problems. The basic problems in retrieval of open contents may be summarized as follows -
Distributed OA resources at global scale
OA resources are available under different software, represented by different metadata sachems, and distributed in different types of services across the globe. Till date there is no comprehensive listing of OA resources subject-wise, language-wise, country-wise (although DOAJ, DOAR and ROAR are providing basic lists).
High percentage of volatile OA resources
Like other Web resource OA resources are volatile in comparison with their commercial counterparts. The change of URL of OA repositories, disappearance of OA journals, non-availability of persistent URLs for most of the resources, no universal standard for unique author identification, missing hyper-links are some of the serious problems in organization and retrieval of open contents.
Large volume of OA resources
OA resources are increasing rapidly in magnitude and in variety but organizing capabilities of search services are failing to keep pace with such geometric growth. For example, a multimedia and multilingual OA resource requires fundamental restructuring of retrieval mechanisms. BASE, an exclusive search service for OA resources, recently reported coverage of 52 million OA resources.
Unstructured OA resources and datasets
Most of the open content service providers like OA repositories and OA journals are not quite serious in policy formulation and in following standard metadata encoding rules, metadata element refinement (e.g. DC. Date may represent date of publication, date of modification, date of uploading etc; therefore element refinement like DC.Date.publication is required for effective organization of OA resources).
Redundant OA resources
As multiple deposit standards (like SWOARD, CRIS-OAR, OA-RJ) are not quite matured yet, authors tend to submit OA resources in many OA retrieval services and thereby leading to redundancy of OA resources. This results in placing unnecessary loads on retrieval systems.
Quality of description datasets for OA resources
Most of the repositories apply simple DCMES (Dublin Core Metadata Elements Set) for describing all sorts of OA resources like journal papers, technical reports, research datasets, thesis and dissertations, images, learning objects, video objects etc. But these special types of resources require domain-specific metadata schemas for describing specific attributes of resources like ETD-MS for describing thesis and dissertations, VRA-Core for image resources, IEEE-LOM for learning objects.
Heterogeneous OA resources
Heterogeneity is the norm in OA. These resources differ in formats, forms, degree of complexity, nature of contents, metadata standards, software in use, back-end database, character encoding, degree of completeness in metadata, supports for interoperability standards and so on. These differences affect efficiency in retrieval considerably.
3.3.3 Retrieval Facilities in Gold OA and Green OA
The OA retrieval systems may broadly be categorized into three major groups on the basis of services rendered by these entities. The major groups are – i) Path Finder services; ii) Federated search services; and iii) Localized search services. The first two groups of services are mostly operating at global scale. The third group of services are developed and maintained by OA publishers, institution-specific repository managers, subject-specific repository managers and volunteer groups. These three broad groups of services are generally using three groups of retrieval utilities – i) using utility of global search engines; ii) use of own search engines; and iii) use of open source text retrieval engines. The above structure may be represented in Fig 29.

This is just an illustrative list of OA retrieval systems under different categories. You may consult Wikipedia92 and OAD93 for a comprehensive list. As it is not possible to discuss here all the OA retrieval systems, the following section provides you brief overview on facilities and services of major OA retrieval systems.
Directory of Open Access Journals94 (DOAJ)
DOAJ provides path finder service to quality controlled Open Access Journals. DOAJ started with the directory services only and later extended retrieval service to search contents of many OA journals listed in DOAJ. It means from DOAJ search interface users can search OA journals at content level. In 2013, DOAJ celebrated its tenth year of operation and the number of articles accessible through the Directory surpassed 1.6 million. DOAJ uses it own search engine for retrieval of contents at two levels – search journal title and search journal articles. It provides (Figure 30) two search interfaces – simple (with provision to search keywords) and advanced search (with provision of using fielded search, Boolean operators, range search etc). It provides no scope for sophisticated search operators like term boosting, fuzzy searching, multilingual search,

OpenDOAR
It is a directory of academic open access repositories, maintained by the University of Nottingham. This OA service lists institutional and subject-based repositories, while also providing a service to search the contents of these repositories. It is an authoritative worldwide directory of academic open access repositories with over 2200 listings.
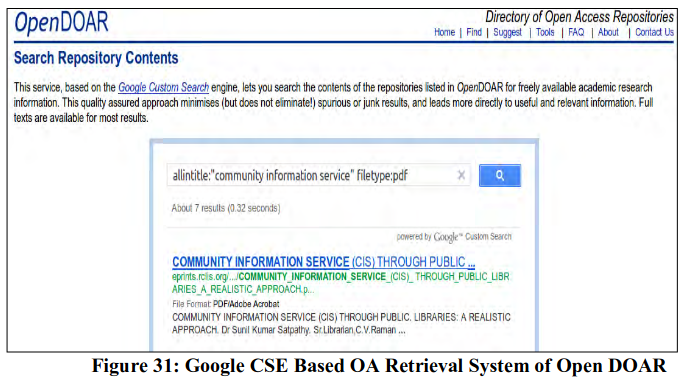
OpenDOAR stared with a simple repository listing of OA repositories but later on started providing content retrieval service by using Google custom search service (CSE). It is now possible to use OpenDOAR to search for repositories as well as to search repository contents96. As it is using one of the most comprehensive generic search engine, an array of special keywords of Google search are available for fine tuning the query representation for efficient content retrieval. These special search operators are phrase search (e.g. “open access journals”), Boolean operators (“open access” AND benefits), allintitle (for multi word search in title filed only e.g. allintitle:“open access journals”), intitle (single word in title e.g. intitle:ORCID), filetype (format of file e..g filetype:pdf), site (to retrieve documents from a specific domain e.g. allintitle:“open access journals” AND site:.ac.in), related (to find sites that are similar to a URL e.g. related:opendoar.org), link (to find pages that link to a certain page e.g. link:eprints.roar.org) etc. The retrieval of contents from OA repositories from openDOAR interface by using special keyword is given in Figure 31.
Directory of Open Access Books (DOAB)
DOAB is a retrieval service of academic, peer-reviewed books from a variety of publishers and available under an Open Access license. It is a service of OAPEN Foundation. This OA service was launched in July 2013. Presently, it contains over 1600 OA books and resources growing at a rapid rate. DOAB supports libraries to integrate the directory into OPAC, helping library users to discover the books. DOAB also supports metadata harvesting through OAI-PMH interoperability standard. Service providers and libraries can harvest the metadata of the records from DOAB for inclusion in their collections and catalogues. The retrieval facilities of DOAB is quite simple and supports only keyword based search. It also provides limited browsing facilities.
Open Access Theses and Dissertations (OATD)
OATD is a valuable retrieval tool for open access graduate theses and dissertations published around the world. Metadata sets of ETDs come from over 800 colleges, universities, and research institutions across the globe. OATD currently indexes 1,839,584 theses and dissertations.
It provides two levels of search interfaces – simple and advanced (Figure 32). This OA retrieval service supports fielded search, Boolean operators and other sophisticated search operators but recent advances in retrieval technology like relevance ranking, fuzzy searching, term boosting are not available in OATD. The use of Web 2.0 utilities are also missing in OATD.
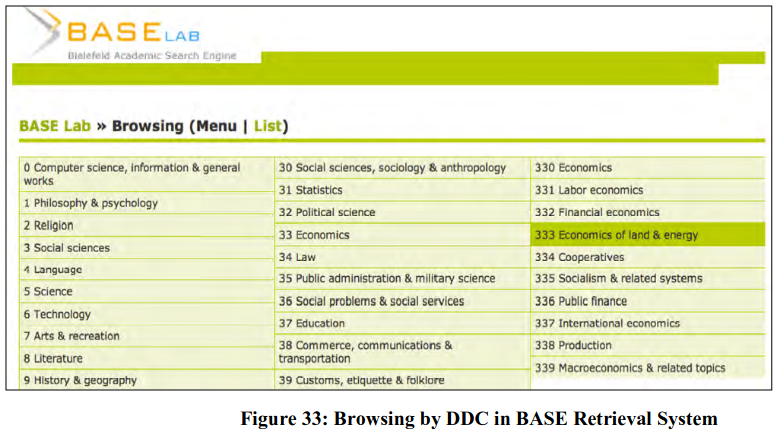
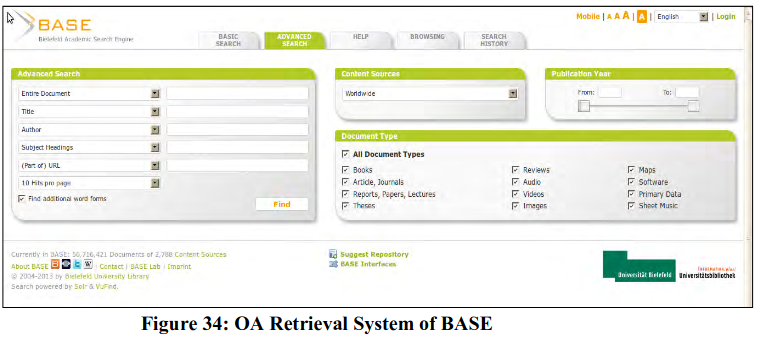
BASE (Bielefeld Academic Search Engine)
BASE (is one of the world's largest retrieval services for academic open access web resources. It also supports an array of sophisticated search operators and end user services. In 2001, Bielefeld University Library started development of federated search service for OA contents on the basis of OAI-PMH interoperability standard and Bielefeld Academic Search Engine (BASE, http://base-search.net) finally appeared in public domain in 2004. Presently, BASE indexes more that 52 million OA resources at global scale (number of documents: 52,615,190; number of content sources: 2,776 as on 18.11.2013). BASE provides two interfaces (a single search field and an advanced search with multiple search fields and sophisticated search options). But the real achievement of BASE is development of Automatic Enhancement of OAI Metadata (AEOM). This AEOM mechanism helps in assigning Dewey Decimal Classification numbers to documents indexed by BASE automatically (Figure 33).
Other major features of this premier OA retrieval system are -
- Multilingual: Multi-lingual search through integration of Eurovoc (end users can search for synonyms and translations from a dataset containing 239,000 terms from 21 languages);
- Multi-modal: Automatic redirection to mobile website and support for all modern platforms like Android, IOS, Windows Phone;
- Multi source: About 75% of the indexed documents in BASE are OA resources, the rest can be accessed up to metadata level.
- Multi operators: Supports for all basic and advanced level search like fielded search, wild card, truncation, range search, positional operators and relational operators;
- Ranking: Sorting of results is by relevance (determined by occurrence of the search term in the title or in the metadata);
- Search refine: Search results can be refined by author, subject, DDC (classification), year of publication, content source, language and document type.
- Search history: Search history for the last ten search queries are displayed, along with the number of retrieved hits;
- RSS feed; Creates an RSS Feed for each query;
- Browsing: Two kinds of browsing is supported - by Dewey Decimal Classification (DDC) and by document types;
- Search plug-in: Provides search plug-in for BASE so that users can directly access search toolbar in browser at user end;
- Personal Search Environment (PSE): Users can create PSE to add favorites and to save search history permanently;
- API: An application programming interface (API) exists which allows integrating the BASE index into local search services like library OPAC;
- Zotero interface: Supports transferring results from BASE to Zotero (an open source citation management software) through add-on;
- User interaction: Users can correct existing DDC class number or suggest DDC class numbers for unassigned contents;
- Filtering: Advanced search interface provides scope to filter results by document types, geographic area and year range;
- Display: Users can control ranking of results by number of options (by relevance, by author, by title, by chronological order etc);
BASE is a feature-rich OA retrieval system (Figure 34) and is acting as model for other such services. BASE is a perfect combination of Vector-space information retrieval model and its integration with controlled vocabulary (Eurovoc) and subject access system (DDC). Moreover, BASE provides facilities to integrate BASE search interface within a local open access repository through an easy-to-implement API and thereby leading to globalization of OA retrieval system.
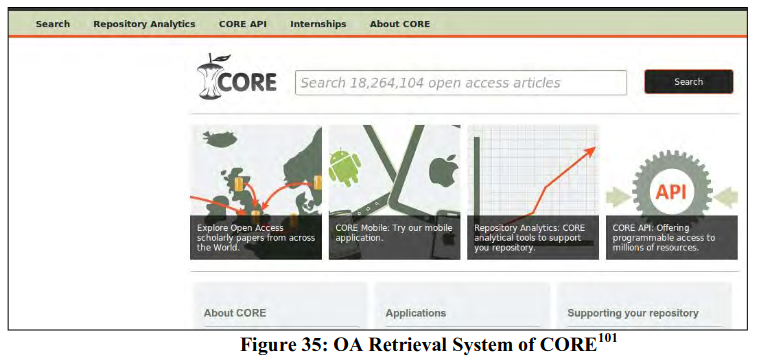
CORE
CORE (COnnecting REpositories) presently facilitates OA retrieval system for scholarly publications distributed across many systems. CORE depends on metadata harvesting through OAI/PMH. JISC, UK initially developed CORE as an aggregation of open access repositories in UK (142 approved OA repositories to be exact) but later on it was extended to cover OA resources at global scale. CORE is accessible through number of options like online portal, mobile device interface, and through repositories and libraries that have integrated CORE with local search service. As a whole, the interfaces may be grouped into five groups – i) CORE Portal ( allows to search and browse OA resources harvested from a wide range of OA repositories through OAI/PMH; ii) CORE Mobile (an Android application to search, browse and download OA resources); iii) CORE Plugin (script to integrate CORE with local repositories to extend search query to CORE); iv) CORE API (allows external systems and services like library OPAC to forward search query to CORE); and v) Repository Analytics (a value-added service to monitor the ingestion of metadata and content from repositories and provides usage statistics).
CORE supports almost all sophisticated search operators but only through simple search interface. But the availability of controlled vocabularies and subject category based browsing are not available till date. CORE retrieval system is supporting only monolingual retrieval of English-language OA contents.
OAISter
OAIster is union catalogue of millions of OA resources, developed by OCLC through OAI/PMH based harvesting from collections across the globe. OAIster includes more than 25 million OA from more than 1,100 sources. Anyone can access OAISter through registration. The retrieval of features of OAISter is powered by WorldCat search services and provides almost all required search operators. It also supports a limited number of web 2.0 tools (like RSS and information mashup).
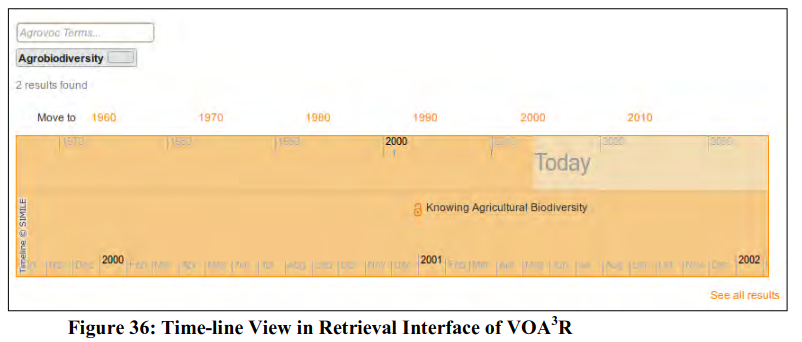
VOA3R (Virtual Open Access Agriculture & Aquaculture Repository)
VOA3R is a social platform with OA retrieval system for students and researchers in agriculture and aquaculture. It integrates OA resources and uses AGROVOC thesaurus to support subject cataloguing and end-user retrieval. Apart from supporting search (simple and advanced) and browse (by author, tile, date etc), it has two unique experimental features - Map view(retrieved results can be shown in a geographical map on the basis of the author’s country or city as mentioned in author affiliation section of the OA resource); and Time-line view (allows items to be categorized by date of publication and this retrieval feature is integrated with AGROVOC thesaurus). The VOA3R OA retrieval system presently covers 2656148 items and uses existing and metadata sets of OA resources to develop an advanced, community-focused integrated service for the retrieval of relevant open contents in the domain of agriculture and aquaculture. The integration of AGROVOC in the retrieval system helps researchers to formulate search query in terms of methods, variables, scientific techniques etc in combination with subject descriptors. The time-line view (see Figure 36) and map view are two important experimental features that may be trend-setters for other OA retrieval systems.
The localized repositories are mostly using open source text retrieval engines. The next section of this unit deals exclusively with the features of text retrieval engines in general and four major retrieval engines (namely Solr, Lucene, Zebra and MGPP) in particular.