3.4 Text Retrieval Engines and Open Contents
Almost all OA content providers are using text retrieval engines or simply search engines for contents indexing, searching of index and ranking of retrieved results. An OA content manager must know the operational features of these text retrieval engines for two reasons – i) to select appropriate text retrieval engine for indexing open contents; and ii) to help users to guide in using search operators for content retrieval. There are three ways to adopt text retrieval engine – i) in house development of text retrieval engine; ii) using a commercial retrieval engine; and iii) using an open source based text retrieval engine. The main problems associated with in-house development of search engine are maintenance, regular up-gradation and total cost of ownership. Commercial search engine is not an attractive proposition for OA service providers both philosophically and economically. On the other hand, open source retrieval engines provide enhanced features, scope of customization and available free of cost. Most of the Green OA software (like DSpace, Greenstone, EPrint etc) and Gold OA software (like Open Journal System, Open Monograph Press) are using open source retrieval engines like Apache-Solr (DSpace version 4.0) Lucene (DSpace upto version 3.2) MGPP (Greenstone version 2.x), Zebra (Koha version 3.x). These open source retrieval engines may be categorized on the basis of following parameters – i) programming language in which it is implemented; ii) how it stores the index (inverted file, database, other file structure), iii) searching capabilities (Boolean operators, fuzzy search, use of stemming, etc), iv) ranking of retrieved results; v) document type handling capabilities (HTML, PDF, plain text, etc); vi) abilities to manage incremental indexes; vii) abilities to integrate related resources on-the-fly; and viii) generic factors such as user base, frequency of update of the software, the current version and the activity of the initiative. The next section discusses features of the major retrieval engines.
3.4.1 Apache-Solr
Solr was created by Yonik Seeley in 2004 as an in-house initiative at CNET Networks and donated to the Apache Software Foundation in early 2006. Solr is presently part of the Apache Lucene project. Solr is a standalone enterprise-grade full text search engine with high performance search server. It can be integrated with web-service through API. Solr is highly scalable, providing distributed search and index replication. It is written in Java and runs as a standalone full-text search server within a servlet container (such as Tomcat). Solr uses the Lucene (a project of Apache Software Foundation) library for full-text search, supports faceted navigation, provides hit highlighting utility and allows query language as well as textual search. The other prominent features of Solr are - HTML administration interface; distributed and scaling of contents volume; search results clustering; plug-in integration; relevance ranking; caching and suitability in embedding in a Java Application. The marked advantages of Solr in comparison with other open source retrieval engines are – i) can drive more intelligent processing through the use of declarative Lucene Analyzer specifications; iii) CopyField functionality that allows indexing a single field multiple ways, or combining multiple fields into a single searchable field; iv) explicit field types that eliminates the need for guessing types of fields during search; v) external file-based configuration of stop word lists, synonym lists, and protected word lists; vi) many additional text analysis components including word splitting, regex and sounds-like filters. Presently, there are a few limitations of Solr – i) does not support relational joins; and ii) does not support wild card at the beginning of a search term. In 2010 Apache Lucene and Apache Solr are merged together by Apache Software Foundation104.
3.4.2 Lucene
Lucene is a simple but robust and powerful text retrieval engine. This retrieval engine is quite suitable for nearly a decade now and especially useful for cross-platform applications. It provides the capabilities of fielded searching, stop world removal, stemming, and the ability to incrementally add new indexed contents without regenerating the entire index. DSpace presently uses Lucene as default search engine. Lucene comes with two main services available: indexing and searching. The indexing tasks are done independently from the search tasks. Both the index and search services are available so that developers can extend them to meet their needs. There are two varieties of Lucene – PyLucene (Java Lucene integrated with Python) and NXLucene (XML based query formulation, indexing and searching). Lucene supports several types of searches that are useful in retrieving open contents. Some of the major features of Lucene are listed below:
- Supports Boolean logic (Boolean operators allow terms to be combined through logic operators. Lucene supports AND, "+", OR, NOT and "-" as Boolean operators);
- Supports Exact Term search or Phrase search (The search term can be a world or a phrase. In phrase search the phrase should be within double quotes. Ex. “institutional repository”);
- Allows Proximity search (Lucene supports finding words are within a specific distance away);
- Provides Range search facility. Range queries allow one to match documents whose field values are between the lower and upper bound specified by the range query. Range search can be applied to any field including Date range. For example, if the search query is: Author:[Mishra to Mukhopadhyay], then the system shows those documents only written by names that fall between ‘Mishra’ to ‘Mukhopadhyay’ only;
- Allows Field Search/ Field-specific Queries (One can search for a term in a particular field. Such as Author:mishra or Title:institutional repository);
- Supports Case sensitive searching, Relevancy ranking, Browsing of indexes, Truncation etc;
- Supports Wildcard and Stemming (Lucene supports single or multiple wildcard searches. The symbol (?) is used for a single character i.e. ‘bo?k’. It may be the word like ‘book’. The symbol ‘*’ is used for multiple characters i.e. ‘bio*’. It may be word like biology or biography); and
- Allows Fuzzy searching (Fuzzy search mechanism in Lucene is based on the Levenshtein Distance, or Edit Distance algorithm)
Lucene was developed by the Apache Software Foundation. It handles field and proximity searching, but only at a single level (e.g. complete documents or individual sections, but not both). Therefore, document and section indexes for a collection require two separate index files. It provides a similar range of search functionality to MGPP with the addition of single-character wildcards, range searching and sorting of search results by metadata fields. Another important feature of Lucene is its ability of term Boosting. Query-time boosts allow searcher to specify which terms are "more important". In other words, Boosting allows users to control the relevance of a document by boosting its term or phrase terms (e.g. "resource description"^4 "metadata encoding" means preference of phrase one over the second phrase). By default, the boost factor is 1. Although the boost factor must be positive, it can be less than 1 (e.g. 0.2). The higher the boost factor, the more relevant the term will be, and therefore the higher the corresponding document scores. A typical boosting technique may assign higher boosts to title matches than to body content matches: (title:interoperability OR title:”open access”)^1.5 (body:interoperability OR body:”open access”).
3.4.3 MGPP
MGPP (MG plus plus) is a new version of MG (Managing Gigabyte), developed by the New Zealand Digital Library Project as an open source retrieval engine. MGPP allows word level indexing to provide fielded, phrase and proximity searching facilities to end users. It supports Boolean operators and Boolean searches can be ranked. Greenstone, an open source digital archive software, is using MGPP as retrieval engine. The granular indexing of MGPP allows integrating document/section levels and text/metadata fields in one index file. MGPP has limitations like - i) no support for Fuzzy searching; and ii) searching may be a bit slower for large collection due to the index being word level rather than section level. The major features of MGPP are:
- text compression using a Huffman-coded semi-static word-based scheme;
- two-level context-based compression of bi-level images;
- lossless compression of gray-scale images for creating image collection;
- indexing algorithms for large volumes of text in limited main memory;
- index compression and processes for Boolean and ranked queries; and
- available with GUI interface to the retrieval system.
Apart from the above features, MGPP provides different search enhancements like folded search, stemming, term-weighted search and improvements over the fielded searching and proximity searching.
3.4.4 Zebra
Zebra is a powerful tool for indexing and searching highly structured data such as MARC records, and GILS records. The Zebra server is freely available for noncommercial applications. Zebra is licensed as Open Source, and can be deployed by anyone for any purpose without license fees. The C source code is open to anybody to read and change under the GPL license. The open source ILS Koha is using Zebra as retrieval engine. Apart from supporting basic search operators and techniques (like Boolean, Relational, Positional operators etc.), Zebra supports following advance and state-of-the art search techniques:
- Term truncation (left, right, left-and-right) and Fuzzy searches (spelling correction);
- Scan (Scan on a given named index returns all the indexed terms in lexicographical order near the given start term. This can be used to create drop-down menus and search suggestions);
- Faceted browsing (allows retrieval of facets for a result set);
- Refine-search (scanning in result sets can be used to implement drill-down in search clients);
- Record Syntaxes (Multiple record syntaxes for data retrieval: GRS-1, SUTRS, XML, ISO2709 (MARC), etc.); Sort (Sorting on the basis of alpha-numeric and numeric data is supported);
- Combined sorting (Sorting on the basis of combined sorts e.g. combinations of ascending/descending sorts of lexicographical/numeric/date field data is supported);
- Relevance ranking (Relevance-ranking of free-text queries is supported using a TF-IDF like algorithm.); and
- Static pre-ranking (Enables pre-index time ranking of documents).
3.4.5 Other Retrieval Engines
The above-mentioned four open source text retrieval engines are mostly in use to support OA retrieval systems. But, there are many other open source retrieval engines that need to be mentioned either because of their historical role or because of their experimental features. For example, SWISH-E is historically important as first plug-n-play text retrieval engine. The HTDig full-text search service was developed by using SWISH-E. It may be considered as pre-runner of modern text retrieval engines. On the other hand, Lemur is an experimental retrieval engine to develop auto summarization and clustering of retrieved results. The following are the examples of open source text retrieval engines that are deployed by different software for retrieval of open contents.
Cheshire II: It’s a logistic regression model based search engine available through FTP from the University of California at Berkeley. It supports Z39.50 protocol to avail distributed search features. The source code of the retrieval engine is available105.
Glimpse: Freely available retrieval engine from the University of Arizona that is designed for efficient indexing (at some cost in retrieval efficiency). Glimpse is not configured for TREC-style evaluations, but these features can be introduced through customization.
IRF: It's a Java toolkit based open source retrieval engine for building IR systems for small applications. The strength of IRF is the object oriented framework that greatly simplifies tasks to modify source code. As Java is designed for platform independence rather than efficiency, the size of the collections that can be handled is quite limited.
Lemur: Lemur is an integrated retrieval engine with Lemur Toolkit, Indri, Galago, Lemur Query Log Toolbar and ClueWeb09 Dataset. It’s an open source retrieval engine toolkit106 for developing search engines, text analysis tools, browser toolbars, and data resources in the area of information retrieval. Apart from supporting regular search features, it supports query based sampling, database based ranking, result merging and summarization.
PRISE: It's a public domain vector space model based retrieval engine developed at NIST. PRISE includes Z39.50 interface for distributed searching. PRISE is configured to run TREC-style evaluations and the source code is available.
SMART: A vector space retrieval engine that is freely available by FTP from Cornell University. Library world knows SMART because of its association with retrieval experiments. It is configured to run TREC-style evaluations and the source code is available.
Xapian: An open source IR system that is designed to handle multilingual text processing and retrieval and available under GPL. It supports structured Boolean queries, relevance feedback, spelling suggestion and many other advanced search features, the popular social bookmarking tool. Delicious is using Xapian as retrieval engine.
In addition, there are also some powerful text retrieval engines such as DataparkSearch Engine; nutch; Swish-e - Simple Web Indexing System for Humans – Enhanced; Webglimpse; and OpenFTS (Open Source Full Text Search engine).
3.4.6 Comparison of Search Features
This section aims to help you in selecting appropriate text retrieval engine for development of Open Access searching and retrieval. The selection framework includes important parameters that required to be supported by text retrieval engine. The framework is divided into three groups – i) Core parameters; ii) Enhanced parameters and iii) Value-added parameters.
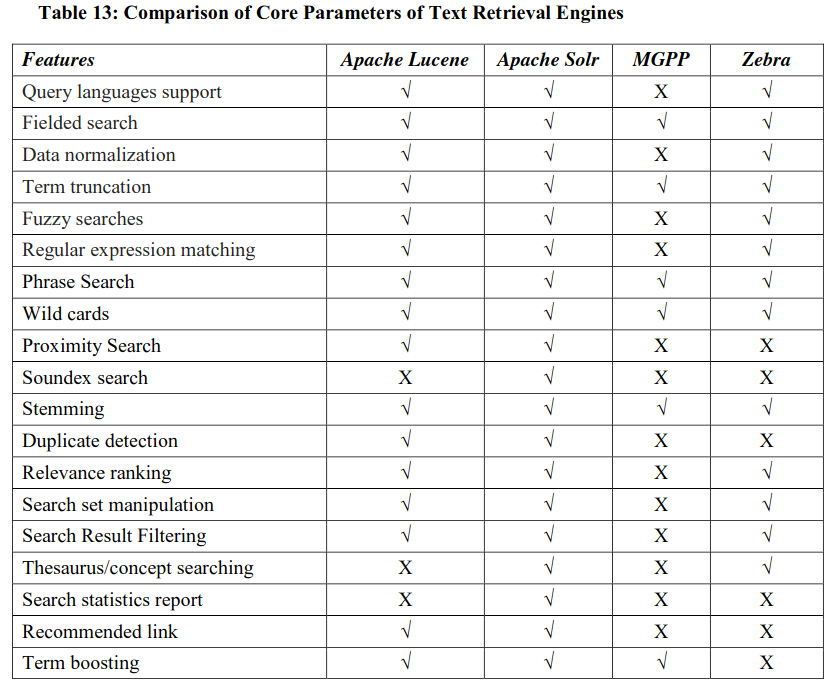
A. Core Parameters
It includes the features that are essential for selected text retrieval engine. The features are listed and compared against four major text retrieval engines (Table 13).
B. Enhanced Parameters
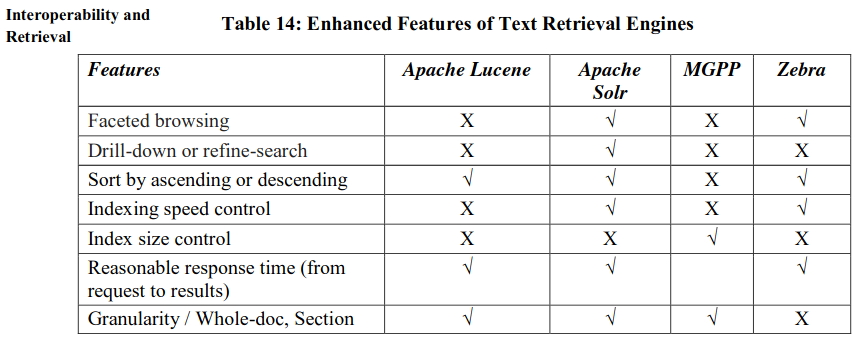
These features are added advantages of a text retrieval engine to help searchers in finding and displaying results according to the needs (Table 14).
C. Value-added Parameters
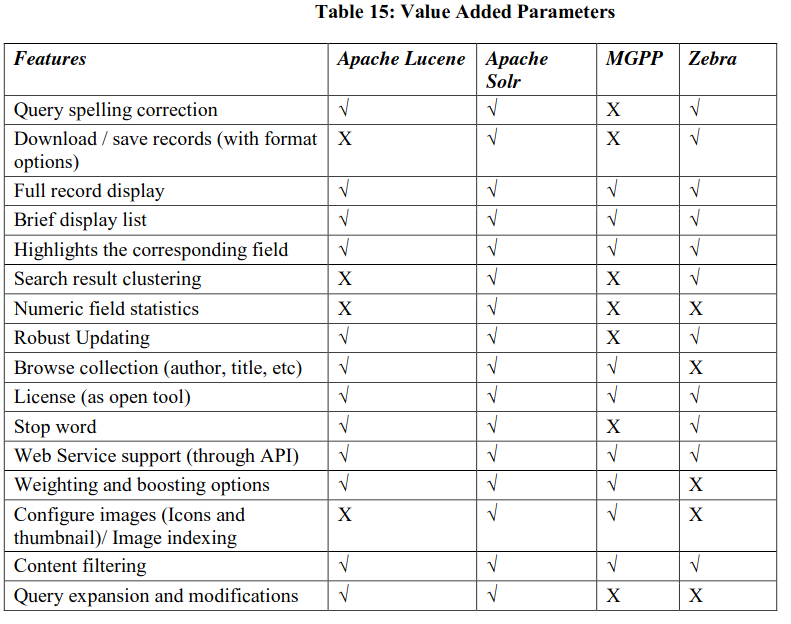
These parameters are additional utilities meant for both indexers and searchers (Table 15).
Please remember that support against a particular parameter by a text retrieval engine may change over the time as these open source text retrieval engines are under continuous up gradation.