3.6 Retrieval of Specialized Open Contents
Michel Lesk (1995) in his seminal paper reported a comparison between development in the domain of Information Retrieval and seven ages of man as described by Shakespeare in As You Like It (Act2, Scene 7, lines 143-166). Lesk predicted many possible achievements of IR in the first decade of 21stcentury. These are – i) Resource Description Framework (RDF) and XML supported Web-enabled IR; ii) Centralized/Federated search services through harvesting; iii) Influence of Semantic Web and Web 2.0 in Information Representation and Retrieval (IRR); iv) Matured multimedia IR systems with information mashup support; v) Integration of digital libraries with online learning environments; vi) Sophisticated multilingual IR with Unicode support; vii) Interactive and collaborative IRR; and viii) Application of Ontology in IRR. Many of these predictions are still in research bed but multimedia IR and multilingual IR are quite matured now. This section covers major aspects of these two retrieval systems.
3.6.1 Multimedia Contents Retrieval
Full text information representation cannot handle non-textual information objects like diagrams, charts, sound, image etc. But web is now increasingly populated by slides, MP3 files, video clips, animated pictures, photographs etc. Moreover, a single digital object may contain text, image, video, and audio. These information bearing objects are called multimedia information. Multimedia information representation and retrieval is one of the hardest challenges to the domain of information retrieval. Multimedia information representation involves three approaches namely - i) Description-based; ii) Content-based; and iii) a combined approach. Description-based approach takes care of information representation through enumeration of descriptive elements like creator, caption, image size, keywords, theme etc. The problem of this approach is that in most of the cases multimedia objects can hardly be described explicitly and objectively. In Content-based approach information representation is based on intrinsic attributes of multimedia objects such as image color, bit-depth, shapes, texture, sound pitch etc. Combined approach is an integration of description-based and Content-based approaches. Researchers of multimedia information retrieval strongly recommend application of integrated or combined approach for Web-enabled access to multimedia based information objects.
3.6.2 Multilingual Contents Retrieval
Text is the most prominent form of information representation, though other representation techniques such as symbols, signs, pictures, sound etc. are also playing important roles. With the progress of multimedia technology, many formats came into existence to deal with multimedia files. However, ASCII remained de factostandard for textual data processing for a long time. ASCII is an 8 -bit (1 Byte) code and can represent maximum of 28 or 256 characters. Most of the ASCII values are reserved for Roman scripts. Although there are instances where ASCII or extended ASCII (such as ISCII) has been in use to represent scripts other than Roman scripts, it is crystal clear that ASCII is inadequate for a multilingual approach to represent various characters from different scripts of the world. The reason is quite simple – 256 characters cannot cover all the scripts of the world. Unicode is a promising open text encoding standard for processing and retrieval of multilingual data. The Unicode Consortium was incorporated in January 1991 to promote the Unicode standard as an international encoding system for information interchange. The Unicode Standard is the universal character-encoding scheme for written characters and text. It defines a consistent way of encoding multilingual text that enables the exchange of text data internationally and creates the foundation for global software. The Unicode Technical Committee (UTC) is the working group within the Consortium responsible for the creation, maintenance, and quality of the Unicode Standard. The UTC follows an open process in developing the Unicode Standard and its other technical publications. In the beginning Unicode was a simple, fixed-width 16 bit encoding. Over the time, Unicode changed this fixed-width encoding style and presently allows three different forms of encoding to meet different requirements:
- UTF-8 attempts to allow legacy systems to use Unicode by coding the characters in the ASCII character set with only eight bits, and encoding characters that are not in the ASCII character set with 16 bits. This is commonly used for Web pages.
- UTF-16 is supplementary characters outside the basic multilingual plane. It encodes most of the world’s major languages in a fixed 16-bit character representation (2 bytes). This is the most common implementation.
- UTF-32 is an actually UCS 4, given a new name. It uses four bytes (32 bits) to encode all possible characters (rarely used).
Many major Web-based search services are Unicode-compliant and support multilingual information retrieval e.g. Google and Yahoo provides Indic-script based retrieval. Apart from the use of Unicode as text-encoding standard, there are two sets of requirements for developing Unicode-compliant Indic script based information retrieval systems. These are - i) system specific requirements and ii) language specific requirements. The first group needs Unicode-compliant Operating System, Text editor, Programming environment and Database management system (Unicode-compliant DBMSs support UTF-8 as standard for native character set). The second set requires language specific tools like Virtual keyboard, Rendering engine and Open type font(s) for respective language. Conjuncts and ligatures are the most font dependent of any scripts. They could be at different positions in different fonts. A rendering engine should be using each font’s glyph substitution tables to contextually render the characters. On the other hand, an open type font has two distinct advantages in a multilingual environment – its cross-platform compatibility and its ability to support widely expanded character sets and layout features. Let’s see how multilingual user interface and retrieval achieved in DSpace repository management software (with reference to an Indic script but this methodology may be extended to any script in the world). The methodology includes three basic steps – i) use of UTF-8 as default character set in backend RDBMS; ii) preparing Java servlet engine to support transaction of multilingual data in UTF-8 encoding; and iii) translation of messages and menus (English language messages and menus stored in DSpace in a central place). This methodology with these three steps create language-specific user interface in DSpace and supports simple and advanced search and retrieval for DSpace.
Step 1: Setting native character set as UTF-8 in back-end RDBMS
The first logical step to achieve multilingual retrieval is to set native character set as UTF-8 in back-end RDBMS (here PostGreSQL) (Figure 42).
Step 2: Setting URIENCODING in Web transactions
The URIEncoding value need to be set as UTF-8 (in DSpace the server.xml file need to be modified) to support multi-script data transaction.

Step 3: Language-specific translation
Translation of messages into target language and script is next logical step. In DSpace we can set different messages.properties file for different languages. The file name must be set by using ISO language code (here file name for Bengali translation is messages_bn.xml). The Figure 43 shows the translation of messages in DSpace in Bengali. This translated messages.properties file must be saved as Unicode file.

Step 4: Retrieval interfaces
The multilingual user interface along with search and retrieval is shown in Figure 44 (as product of the above-mentioned three steps). It supports field-specific search, Boolean operators and sorting order of results.
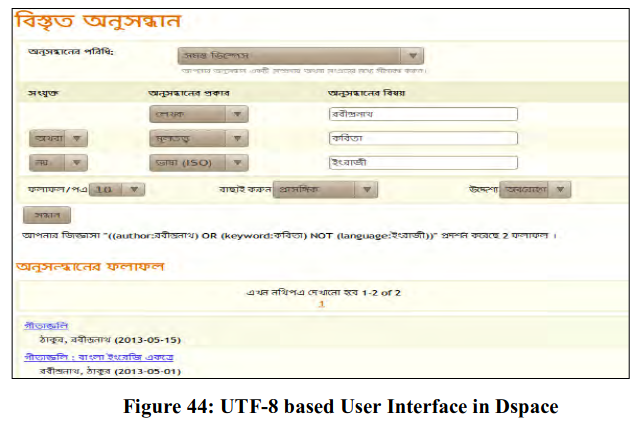
This interface supports display of Boolean operators in target language, relevance-ranking and sorting in ascending/descending order. The only problem of this method is that it cannot sort chronologically when date value entered in other than Indo-Arabic numbers.