1.2 Research Lifecycle
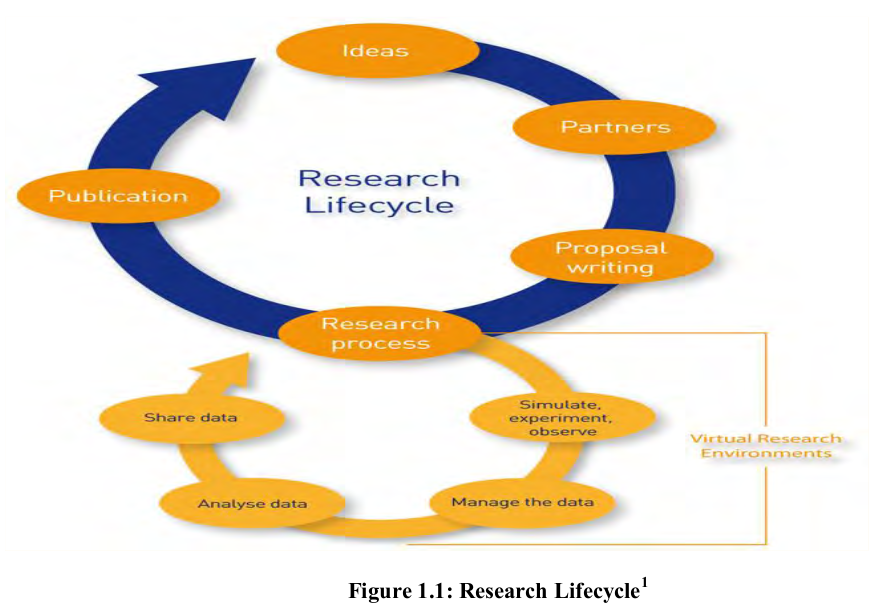 The research lifecycle is a representation of the activities that occur throughout a research process. It starts with an idea to pursue, followed by data collection, and data analysis, that continues with interpretation of the analysis in the form of a research publication. Grouped into sequential steps or stages, research lifecycle covers everything from conceptualization to knowledge transfer. Each stage comprises a set of related activities that culminate in a significant outcome that is then carried forward to the next stage. The research output could be shared in the form of a book or article, blog, presentation, or through any other communication channel. These primary research outputs once disseminated provide an opportunity for the scholarly community to engage in discussions, debates, and further study on the topic at hand. The outcome of further study starts the cycle anew. By linking together a series of stages in the research process in a logical sequence, the research lifecycle is represented. Within the research lifecycle, several stages involve the production and management of data and metadata apart from the scholarly publication which is the ultimate outcome.
The research lifecycle is a representation of the activities that occur throughout a research process. It starts with an idea to pursue, followed by data collection, and data analysis, that continues with interpretation of the analysis in the form of a research publication. Grouped into sequential steps or stages, research lifecycle covers everything from conceptualization to knowledge transfer. Each stage comprises a set of related activities that culminate in a significant outcome that is then carried forward to the next stage. The research output could be shared in the form of a book or article, blog, presentation, or through any other communication channel. These primary research outputs once disseminated provide an opportunity for the scholarly community to engage in discussions, debates, and further study on the topic at hand. The outcome of further study starts the cycle anew. By linking together a series of stages in the research process in a logical sequence, the research lifecycle is represented. Within the research lifecycle, several stages involve the production and management of data and metadata apart from the scholarly publication which is the ultimate outcome.
The research lifecycle diagram by the Joint Information Systems Committee (JISC) represented below shows an interconnected bicycle, the top one showing the research lifecycle, and emanating from the research process stage the data lifecycle interwoven below it.
The research lifecycle comprises three major processes:
- Research Planning,
- Data Collection and Management, and
- Scholarly Communication.
Data Management Consulting Group (DMConsult) of the University of Virginia Library representation of the steps in the Research Life Cycle (Fig.1.2 ) is quite library centric where library services can be engaged. It focuses more on the data management aspects including metadata as well.
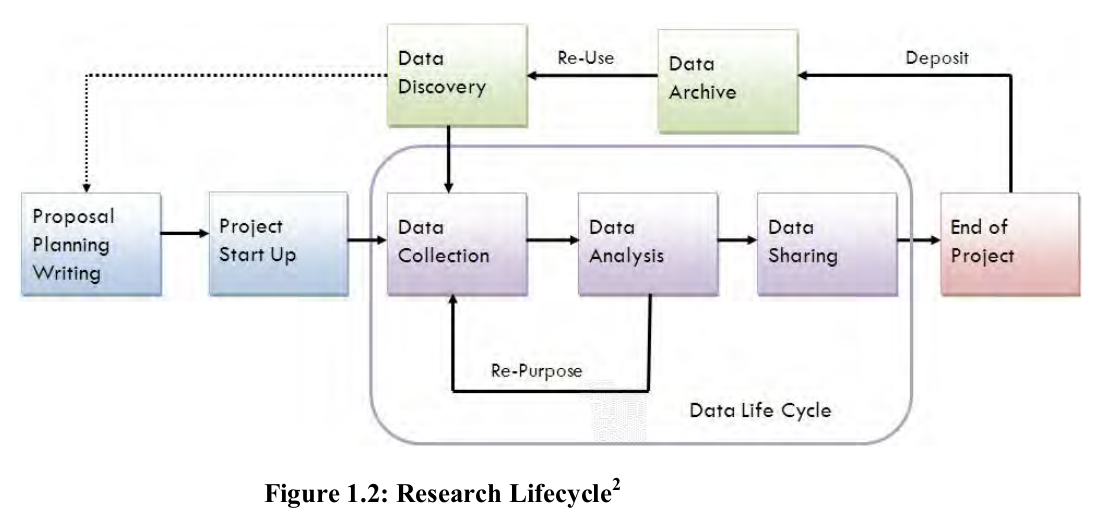
The figure above broadly categorises the research lifecycle into following major components:
- Proposal Planning and Writing – This step includes review of existing data sets, decision on whether to produce a new dataset (or combing existing), investigation of archiving challenges, consent and confidentiality, Identify potential users of data, cost analysis for archiving and consultation with archivists.
- Project Start Up – this step involves preparation of data management plan, take decisions about documentation form and content and conduct pilot test of materials and methods.
- Data Collection – For data collection one needs to look into the best practices. Collected data needs to be properly organized and also one needs to arrange for backups and storage. This step will also require quality assurance mechanism in place for data collection and also decision on access control and security aspects.
- Data Analysis – This step includes managing file versions, document analysis and file manipulations.
- Data Sharing – Depending on the data sharing policy decision on file formats has to be made. Consultation of archivist for advice on data storage may be required and cleaning up of redundant data needs to be looked into.
- End of Project- In the final step one may write paper/ article, submit report on findings and deposit data in a data archive/ repository.
Managing data in a research project is a process that is most crucial and runs throughout the research lifecycle. Good management of data is essential to ensure that data is preserved and remains accessible in the long-term, so that it can be re-used by other researchers. When managed and preserved properly research data can be successfully used for future scientific purposes. Researchers need help to manage their data and this is where libraries can play a major role. One of the most significant changes in the recent years has been the widespread recognition of data as an asset.
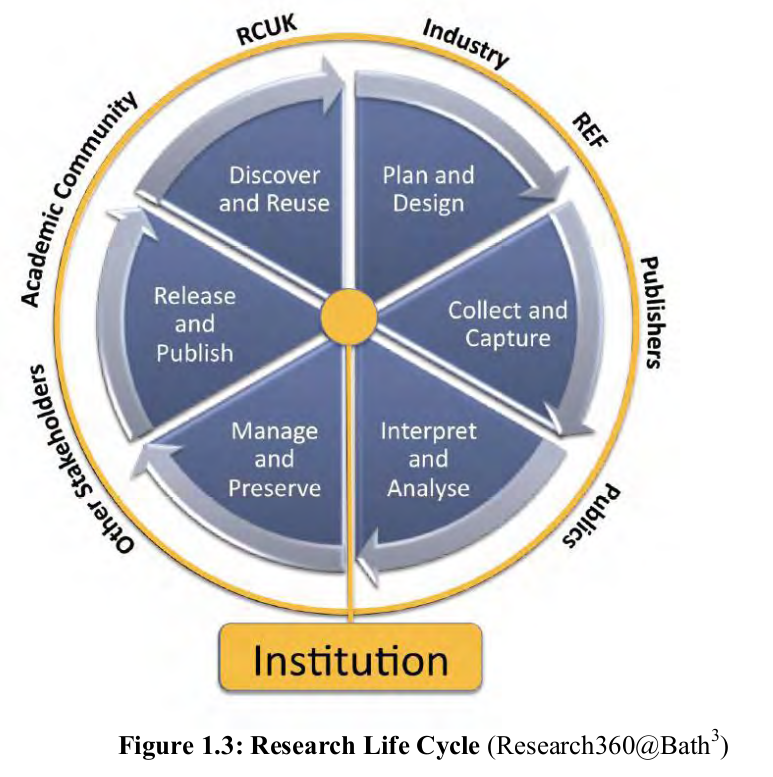
Liz Lyon depicts the research life cycle (Research360@Bath) combining the researcher and the library perspectives and adding to that the context of community or stakeholders. The model is based on a partnership approach involving UKOLN-DCC, Library, IT services, Research Support Office and Doctoral Training Centres.
Data management planning is the starting point in the data life cycle. Data Management Plan needs to take into consideration: i) Information about the data including metadata and their format, ii) policies for access, sharing, and reuse of data, iii) long-term storage and data archiving plan, and iv) budget considerations for data management. After planning, assess what it takes to fulfill in terms of infrastructure, staff skills and resources, and management support. Once data collection or capture (in case of pure research) is done the next step is data analysis. Analysis tools for scientific data generally comprise programming languages, statistics and analysis tools, and workflow tools. For good data management researchers need to engage in Quality assurance mechanism to ensure data quality before its collection and Quality control for monitoring and maintaining data quality during the study. One needs to have mechanisms to check errors of omission and commission at data entry level. Once data is fed next step is managing and preservation of data where library can play a major role. At this stage metadata needs to be added so that the researcher can communicate with other scientists who may like to re-use the data. To bring in interoperability, using metadata standards is important. The next stage is sharing and publishing data. Data sharing basically refers to citing data and for long term preservation a persistent or long-term identifier is an absolute must. It is therefore, important that while publishing data it needs to include the citation data with title, date, authors, abstract, and persistent identifier (DOI, URI etc.) so that they can be easily discovered and reused.
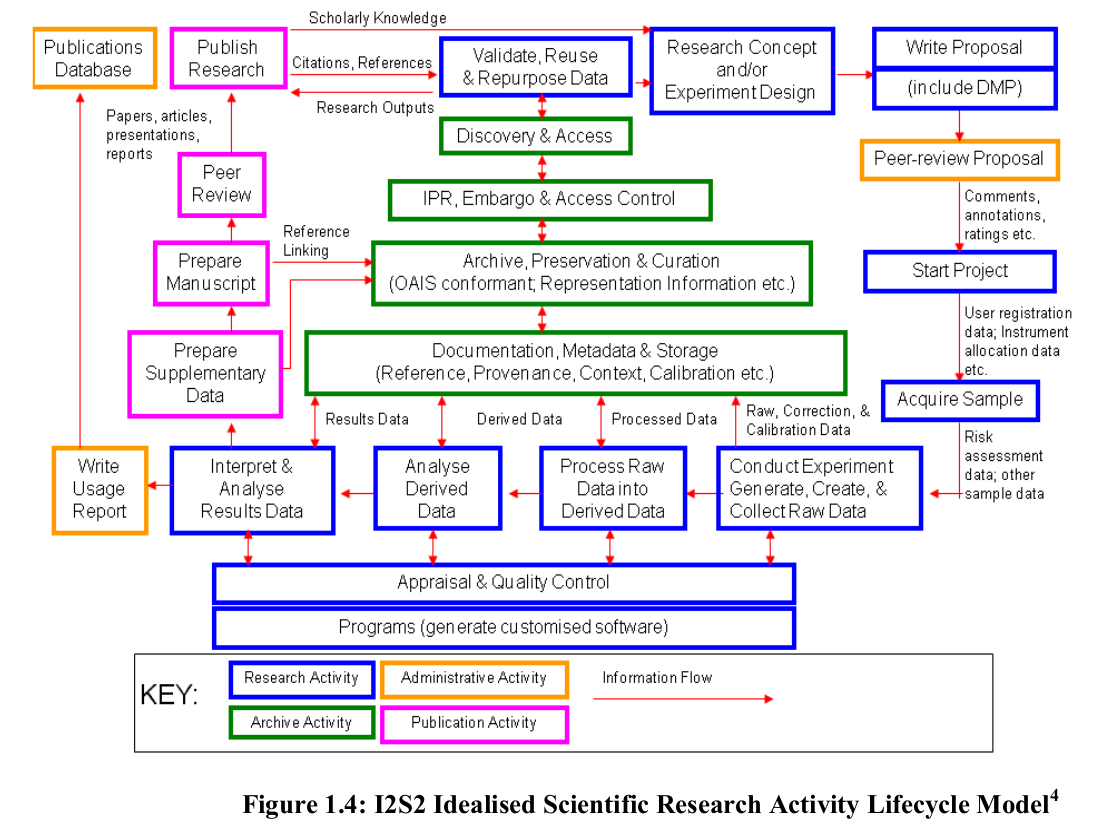
I2S2 Idealised Scientific Research Activity Lifecycle Model represents the processes and phases of research lifecycle from a typical physical science experiment project perspective. The stages include:
- development of the research proposal;
- peer-reviewing of the proposal;
- carrying out of the experiment;
- processing, analysis and interpretation of the data;
- reporting and publishing in various forms as research outputs;
- appraisal and quality control;
- documentation including metadata and contextual information;
- storage, archive, preservation and curation; and
- IPR, embargo and access control.
This very comprehensive representation of the research lifecycle is given Fig.1.4.
Bo-Christer Björk in 2007 developed a comprehensive model for the scholarly communication life cycle using the formal process-modelling method IDEF02, a standard tool used in business process re-engineering. This was further refined by John Houghton and Bo-Christer Björk in 2008.The model encompasses five basic scholarly communication process activities and each of these comprising numerous sub-processes. The basic components are:
- Perform research and communicate the results
- Publish research outputs
- Facilitate dissemination, retrieval and preservation
- Study publications and apply the knowledge derived.