2.3 Interoperability Initiatives
Open access resources are increasing steadily right from the first decade of 21stcentury. Recently BASE (an exclusive search engine for open contents) is reported to achieve indexing of 52 million open access resources. In this distributed, growing and complex open-access information environment interoperability holds the key for effective dissemination of open knowledge objects. We have already discussed different types of interoperability in previous section. There are seven levels of interoperability in the domain of open access resources as prescribed by COAR and DL.org. The semantic interoperability in open access domain is still in research bed. Therefore, in this section, we are going to study different interoperability initiatives under six major heads.
2.3.1 Metadata-level Interoperability Initiatives
Metadata interoperability is possibly the most visible initiative in the open access domain. Almost all open access repositories support metadata harvesting. It means sharing of metadata across an array of open access repositories. OAI/PMH is presently the only standard available in this direction. Open Archives Initiative – Protocol for Metadata Harvesting (OAI/PMH) is a low barrier and low-cost mechanism for harvesting metadata records from ‘data providers’ to ‘service providers’. It works on the basis of Six Verbs (see section 4.2.4.2). OAI/PMH has its root in open access movement initiated by the establishment of eprint archives (arXiv, CogPrints, NACA (NASA), RePEc, NDLTD, NCSTRL) and developed by Open Archive Initiative. The present release of the protocol is OAI/PMH Version 2.0. There are many global open access services working on the basis of OAI/PMH protocol such as OAIster74, Europeana75 and Connecting-Africa76. Almost all the open source repository management software like DSpace, Eprint, Fedora and Greenstone are compliant with OAI/PMH Version 2.0 and allows service providers to harvest metadata of deposited items in these software.
2.3.2 Content-level Interoperability Initiatives
Cross-system contents transfer aims – i) to manage multi-deposit; ii) to handle multi-authored and multi-institutional knowledge objects; and iii) to integrate digital knowledge archive and research administration. There are three major interoperability initiatives in this direction - SWORD, OA-RJ and CRIS-OAR respectively.
SWORD (Simple Web-service Offering Repository Deposit)
SWORD is a lightweight protocol to facilitate multiple deposits. It helps authors/submitters to deposit knowledge object into multiple repositories in one go. SWORD was first developed in 2007 under the sponsorship of JISC, UKOLN. It is based on AtomPub standard to achieve interoperability. This protocol facilitates transfer of metadata, and metadata plus digital objects (including compound digital objects). It supports content transfer for different combinations like Publisher to Repository, User's machine to Repository, Repository to Repository, Conference management system to Repository. It also supports repository bulk ingest and collaborative authoring.
URL: http://swordapp.org
Present version: Version 2.0
Implementation: DSpace, Fedora, EPrints (recent versions only)
Documentation: http://swordapp.org/the-sword-course
OA-RJ (Open Access Repository Junction)
OA-RJ is a protocol to support automatic deposition of multi-authored and multi-institutional knowledge objects into multiple repositories (both Institution-specific and Subject-specific repositories). OA-RJ aims to reduce the problems related to simultaneous submission into multiple repositories –author’s own institutional repository (IR), co-authors’ IRs, subject specific repositories, and funder repositories. It uses the ORI (Organization and Repository Identification) to achieve interoperability in workflows. OA-RJ helps submitters to refer and redirect to appropriate repositories through the use of API.
URL: http://edina.ac.uk/projects/oa-rj/index.html
Present version: Version 1.0 Sponsor: EDINA, JISC
Documentation: http://edina.ac.uk/projects/oa-rj/about.html
CRIS-OAR (Current Research Information and Open Access Repositories)
The aim of this interoperability initiative is to define a metadata exchange format for integrating research information system and open access institutional repository with the help of an associated common vocabulary system. It transfers metadata of publications automatically from research information system to institutional repository with option (from authors) to integrate full-text resources.
URL: http://www.knowledge-exchange.info/
Present version: Version 1.0
Sponsor: Knowledge Exchange
Documentation: https://infoshare.dtv.dk/twiki/bin/view/KeCrisOar/WebHome
2.3.3 Network-level Interoperability Initiatives
This group of interoperability initiatives is dedicated to develop coordinated network of digital repositories at the national and regional levels. These initiatives aim to achieve high degree of interoperability and enhanced services to end users of open access resources. There are three major initiatives in this direction namely DRIVER, OpenAIRE and UK RepositoryNet+.
DRIVER (Digital Repository Infrastructure Vision for European Research)
DRIVER aims to create an infrastructure for open-access repositories in Europe. It provides a set of best practice guidelines (known as DRIVER guidelines) for content provider to build pan-European research infrastructure. The guidelines include – i) local data management policies; ii) OAI/PMH applications; iii) value-added services for repositories; iv) essential standards and processes for standardization; and v) development of D-NET v 1.0 toolkit to setup national repositories.
URL: http://www.driver-community.eu/
Present version: Version 2.0 of DRIVER Guidelines
Sponsor: DRIVER Consortium, EC
Documentation: http://www.driver-support.eu/documents
Implementation: Belgium DRIVER Portal, RCAAP – Portuguese portal, Recolecta – Spanish portal
OpenAIRE (Open Access Infrastructure Research for Europe)
OpenAIRE initiative is based on DRIVER guidelines. It provides guidelines and standards to integrate OA repositories and OA journals by following FP7 OA policy and ERC Guidelines for OA. This initiative also prescribes the metadata format to manage usage data (including events and statistics) and also describes appropriate transfer protocols for the purpose (with emphasis on usage data of scholarly literature related to EC funded projects).
URL: http://www.openaire.eu/
Present version: Version 2.2, 2010
Sponsor: OpenAIRE Consortium, European Commission
Documentation: http://www.openaire.eu/en/support/guides/repository-managers
Implementation: ORBi – Open Repository and Bibliography (http://orbi.ulg.ac.be/)
KOPS - IR of Universität Konstanz (http://kops.ub.uni-konstanz.de/)
UK RepositoryNet+
UK RepositoryNet+, also known as RepNet, is an initiative to support open access interoperability through socio-technical infrastructure to support deposition, curation and content exposure. RepNet concentrates on four areas – Deposit (application of OA-RJ and ORI); Policies (brings together SHERPA RoMEO and JULIET); Reporting (use of IRUS-UK to create COUNTER-compliant repository usage at item level); and Innovation.
URL: http://www.repositorynet.ac.uk/
Present version: Version 2.0 of DRIVER Guidelines
Sponsor: DRIVER Consortium, EC
Documentation: http://www.driver-support.eu/documents
DINI Certificate for Document and Publication Services
Although this initiative is not a technical specification for OA network level interoperability but it provides a comprehensive socio-legal guideline in maintaining OA repositories. The German Initiative for Network Information (DINI) maintains DINI certificate (DINI releases new version in every three years in German, Spanish and English languages) that specifies minimum essential elements for sustainable maintenance of open access repositories in terms of technical, organizational, and legal aspects. DINI is a national certificate and provides DINI seal to repositories to assure trustworthiness and quality of the services. Many German OA initiatives like EconStar, pedocs of German Institute for International Educational Research, edoc of Humboldt University are DINI certified OA services. DINI Certificate supports many international interoperability initiatives such as OAI-PMH, Dublin Core and fully compliant with DRIVER.
URL: www.dini.de/dini-zertifikat/english
Present version: Year 2010 Version (Year 2013 Version is due)
Sponsor: DINI
Documentation: http://nbn-resolving.de/urn:nbn:de:kobv:11-100182800
2.3.4 Statistics and usage data-level Interoperability Initiatives
Citation is an important part of scholarly communication process. With the advent of ICT-enabled scholarly communication, different other parameters like number of hits, number of downloads, ranking by popularity are considered as parameters for measuring quality of research output. In OA (both Green OA and Gold OA) log entries store usage events. Analysis of log entries may be utilized for assessing the usage of OA objects. Many value-added services may also be generated from usage statistics like creation of a network of related resources, linking researchers working in the same area and development of recommender system. Obviously, usage statistics based services can be much more effective through integration of usage data from different OA journals and OA repositories. The usage statistics service is considered as an important value-added service for open contents management systems. Apart from the contributors and users of open access resources, funding agencies are also interested in availability of integrated usage data to measure research impact and to analyze trends over time. The major challenge is to develop a techno-organizational model for the recording, reporting and consolidation of usage of open contents available from OA journal publishers, toll publishers, aggregators, institutional repositories and subject repositories. In open access repositories multiple-deposit is a common feature. For example, open contents may be written by multiple authors from different institutions and thereby may be deposited in multiple repositories including publisher portals. In such cases availability of complete usage data for a specific open content is simply beyond the scope of a single repository. Many guideline and best practices in OA advocated for the provision of usage data from repositories to end users (such as DRIVER, OpenAIRE, RepNet etc). OpenAIRE specifies the metadata format that can be used to incorporate information of usage events and describes appropriate transfer protocols. It also prescribes a model for harvesting usage statistics from OAI/PMH compliant repositories (see Figure 14).
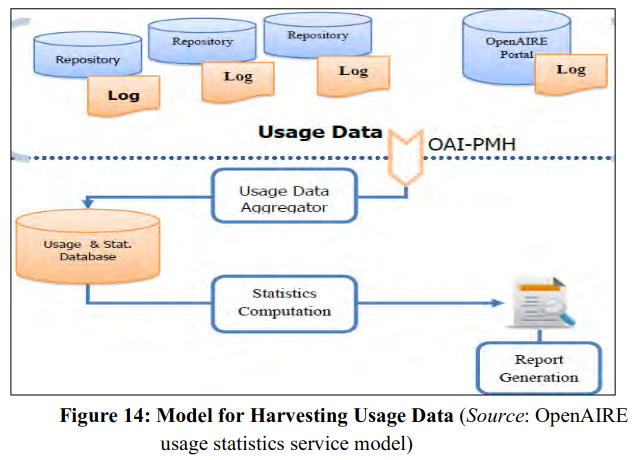
Some of the well-known interoperability initiatives in this direction are:
COUNTER (Counting Online Usage of Networked Electronic Resources)
You have already understood from the above discussion that standardization is required for comparing, analyzing and aggregating usage data from distributed repository services. Uniformity is required primarily at two levels – i) standards for storing usage data in a uniform format; and ii) standards for transfer of usage data across repositories. The project COUNTER is the first such initiative in this direction. It may be considered as the mother project for standardization of usage data and statistics. Most of the large-scale national repository initiatives already defined standards for COUNTER compliant usage statistics (for example PIRUS in UK, OA-Statistics in Germany, SURFSure in Netherlands and NEEO in Belgium). COUNTER allows four categories of non-textual resource- image, video, audio and other. COUNTER is a code of practice for managing usage data for digital resource repositories.
URL: http://www.projectcounter.org/index.html
Present version: Stable
Sponsor: UK based initiative
Documentation: http://www.projectcounter.org/code_practice.html
SUSHI (Standardized Usage Statistics Harvesting Initiative)
The SUSHI is a protocol designed for the transmission and sharing of COUNTER-compliant usage data from repositories, OA publishers, toll publishers, aggregators and other bibliographic service providers who are able to present usage data in COUNTER-compliant format. This protocol is a product of NISO (National Institute for Standards Organization, US) and aims to alleviate automated integration of large-scale usage data from different sources including open access service providers. The SUSHI protocol77 also includes a Schema specification in XML format () that allows integration and aggregation of COUNTER-compliant usage reports quickly and easily by repository manager at local level. The protocol is a complete pack that includes Documentation, SUSHI Tools, SUSHI Schemas, SUSHI Reports Registry, SUSHI Server Registry, SUSHI Developers List and SUSHI FAQs.
URL: http://www.niso.org/workrooms/sushi/
Present version: Stable
Sponsor: NISO, US
Documentation: http://www.niso.org/workrooms/sushi/
KE-USG (Knowledge Exchange Usage Statistics Guidelines)
The Knowledge Exchange Usage Statistics Guidelines (KE-USG) is an important initiative in aggregating and transferring usage data from OA journals and OA repositories. It is basically a set of guidelines that includes metadata format for usage data (the format is compliant with OpenURL Context Objects), prescribes protocol for transferring usage data across repositories (SUSHI or OAI/PMH), suggests rules for normalizing usage data (issues related with 'robot filtering' and 'double clicks') and provides a framework of interaction (how providers of usage data and service providers can interact and transfer data including legal boundaries). The three major national level initiatives in usage data namely PIRUS2 in UK, OA-Statistics in Germany, SURFSure in Netherlands have contributed considerably in developing KE-USG. These initiatives are completely compliant with KE-USG.
URL: http://www.knowledge-exchange.info/Default.aspx?ID=365
Present version: Version 2.0 stable
Sponsor: Knowledge Exchange (cooperation from JISC, DEFF, SURF and DFG)
Documentation: http://wiki.surf.nl/display/standards/KE+Usage+Statistics+Guidelines+Work+group
NEEO (Network of European Economist Online)
Network of European Economists Online (NEEO) is an international consortium of 18 universities. NEEO maintains a subject repository in the domain of Economics. This initiative, originated in Belgium, provides a set of guideline to aggregate item level usage data based on article identifier and user identifier. It also developed extensive guidelines for – i) creation of usage statistics; ii) aggregation of usage statistics; and granularity for usage statistics for designing recommender system. NEEO differs from COUNTER in view of the followings - typically publisher usage data is available in COUNTER format (NEEO provides platform for both OA and toll publishers); COUNTER uses journals as lowest level of granularity (NEEO emphasizes item-level usage and thereby more granular than COUNTER). NEEO uses three major standards SWUP (the Scholarly Works Usage Community Profile) for usage data description, OpenURL ContextObject for IR log analysis and OAI/PMH protocol for transferring usage data.
URL: http://www.neeoproject.eu/
Present version: Version 1.4
Sponsor: NEEO-WP 5
Documentation: http://homepages.ulb.ac.be/~bpauwels/NEEO/WP5/
OA-Statistik
Open Access Statistics (OAS) aims to support open access movement by promoting the usage data and statistics. OA-Statistik is a German project to aggregate globally available usage data mainly from open access service providers by providing technical infrastructure for collecting, processing and presenting usage data at item level. The infrastructure is a two-layer system –i) layer 1 collects from OAS data providers, processes usage data and presents processed data in standard interface to layer 2; ii) layer 2 includes a central OAS service provider which harvests usage data from OAS data providers, calculates statistics from usage data and finally makes analytical results available to participating repositories and other value-added service providers.
URL: www.dini.de/projekte/oa-statistik/english
Present version: Version 5
Sponsor: DINI, Germany
Documentation: http://www.dini.de/fileadmin/oa-statistik/projektergebnisse/Specification_V5.pdf
PIRUS (Publishers and Institutional Repository Usage Statistics)
Usage-based metrics is now accepted by research community as a tool to assess the impact of journal articles. PIRUS is a JISC, UK funded initiative in view of the emergence of online usage data as an alternative measure of article and journal value. PIRUS is a code of practice for managing usage data and is considered as open international standard in the domain. The aim of this initiative is to provide a set of guideline and standards in recording, exchange and interpretation of online usage data at the individual article level. In fact PIRUS is granular extension of COUNTER standard at the item level. Although it is primarily meant for COUNTER-compliant repositories, Non-COUNTER-compliant service providers may also use the Secondary Clearing House services to generate PIRUS compliant usage reports from their raw usage data. The major objectives of PIRUS are:
- To define a core set of standards for repositories for producing usage statistics;
- To collect and process usage statistics at the individual article level
- To derive consolidated PIRUS usage statistics per article;
- To provide a central source of validated, consolidated PIRUS usage statistics for individual articles; and
- To develop a suite of open source tools for generating COUNTER-compliant usage data at item level;
PIRUS has a close liaison with the project COUNTER. But PIRUS gives more emphasis on item level usage data through a framework of standards that include article types to be counted; article versions to be counted; data elements to be measured; definitions of these data elements; content and format of usage reports; requirements for data processing; requirements for auditing; and guidelines to avoid duplicate counting. At the item level, PIRUS suggests to include following metadata elements – i) either print ISSN OR online ISSN; ii) article version, where available; iii) article DOI; iv) online publication date or date of first successful request; and v) monthly count of the number of successful full-text requests. Other optional but desirable metadata elements are - i) journal title; ii) publisher name; iii) platform name; iv) journal DOI; v) article title; and vi) article type. The item level granularity in PIRUS is achieved through two additional metadata – article DOI and ORCHID as author identifier.
URL: http://www.projectcounter.org/pirus.html
Present version: Release 1, October 2013
Sponsor: JISC, UK and Mimas (University of Manchester)
Documentation: http://www.projectcounter.org/documents/Pirus_cop_OCT2013.pdf
SURE (Statistics on the Usage of Repositories)
The project SURE is an initiative by a group of Dutch universities. It is funded by SURF foundation. It aims to coordinate and aggregate usage data from repositories in Netherlands. The technical specification of the SURE project is fully compatible with the national and international initiatives in the area of usage statistics. The SURE project uses OpenURL Context Object Schema and the schema is compatible with other similar initiatives like PIRUS in UK, NEEO in Belgium and OAS in Germany. This project uses NARCIS portal (the gateway to scholarly objects in Netherlands) to store usage data. The dashboards provide usage statistics for individual objects (with different visualization facilities) to different service providers in OA. Local repositories can also use API or Widget (developed by SURE project) to integrate usage data at respective user interfaces (see http://repositorymetrics.narcis.nl/). The SURE project is also planning to provide matrices for individual contributor on the basis of Digital Author Identifiers (DAIs).
URL: http://wiki.surf.nl/display/statistics/Home
Present version: Draft version available
Sponsor: Open Society Institution (OSI) with technical support from Knowledge Exchange project
Documentation: http://wiki.surf.nl/display/standards/KE+Usage+Statistics+Guidelines
2.3.5 Identifier-level Interoperability Initiatives
As already discussed, unique identification schemes are essential to ensure cross-system interoperability in terms of digital scholarly objects, contributors and datasets. Use of unique identifiers in achieving interoperability is not a new idea in the area of library and information science. As a library professional you know the value of name authority data to identify authors consistently and the role of ISBN/ISSN/ISMN etc to identify documentary resources uniquely. In last few years different standards have emerged in the digital scholarly resource landscape such as standards for unique author identification (e.g. ORCID and AuthorClaim), standards for object identification (e.g. DOI, Handle system, PersID) and recently standards for dataset identification (e.g. DataCite). All these emerging standards and services help to support open access interoperability.
Author Identifiers
There are some established author identifier schemes like RePEc Author Service (RAS) in the subject field Economics and some emerging services like AuthorClaim and ORCID. RePEc is mainly concerned with one particular discipline and therefore cannot be considered as universal standard in the area of author identification but it has already passed ten years of service and a large pool of researchers in Economics are registered members of RAS. Similarly E-LIS (a subject-specific repository in Library and Information Science) has its own author identification system. The two universal author identification systems (AuthorClaim and ORCID) have considerably been influenced by the said subject-specific author identification systems. For example, AuthorClaim is developed by Thomas Krichel, the creator of RAS. But we should remember that author identifier has no value if it is not linked with biographic and bibliographic information. The integration of author ID, his/her biographic data (institute – past and present, co-authors, subject area etc) and his/her scholarly works (with necessary bibliographic data elements) creates an author profile, and this can be done either by the system issuing the identifier, or by the systems that collect scholarly contributions, or by one or more other systems.
AuthorClaim Registration Service
Thomas Krichel (the creator of RePEc and RAS) developed AuthorClaim with the fund support from Open Society Institute (OSI) under ACIS project78. It aims to create profile of scholars in a bibliographic database for linking the authors uniquely with the scholarly contributions. This author identification system has following features:
- Allows authors to build a profile in AuthorClaim through registration (only prerequisite is e- mail ID of author);
- System searches for related publications and ask author to identify his/her publications (there is option for manual entry for different types of resources);
- Bibliographic databases that use AuthorClaim record can link the profile page of author;
- Distinguishes authors from each other even with the same name;
- Provides regular statistics about downloads and citations to authors; and
- Helps authors and other service providers to compute various rankings related to productivity (e.g. h-index).
URL: http://www.authorclaim.org
Status: Operational
Sponsor: Open Society Institute (OSI) under ACIS project (see http://acis.openlib.org/)
Open Researcher and Contributor ID (ORCID)
ORCID is an open international initiative to provide a registry of unique researcher identifiers at global scale. It offers a method to connect scholarly contributions with author identifiers. Additionally, ORCID also allows cooperation with other identifier systems. This author identification system has following features -
- Author creates their profile and links profile with his/her list of publications (allows import of bibliographic data elements through standards like RIS, bibtex etc.;
- Author can enter ORCID ID during submission of digital resource in repositories;
- Repositories can ingest ORCID record into repository software architecture; and
- Publishers can use ORCID ID of an author during submission of manuscript.
URL: http://www.orcid.org
Status: Operational, stable from October 2012
Sponsor: ORCID Society
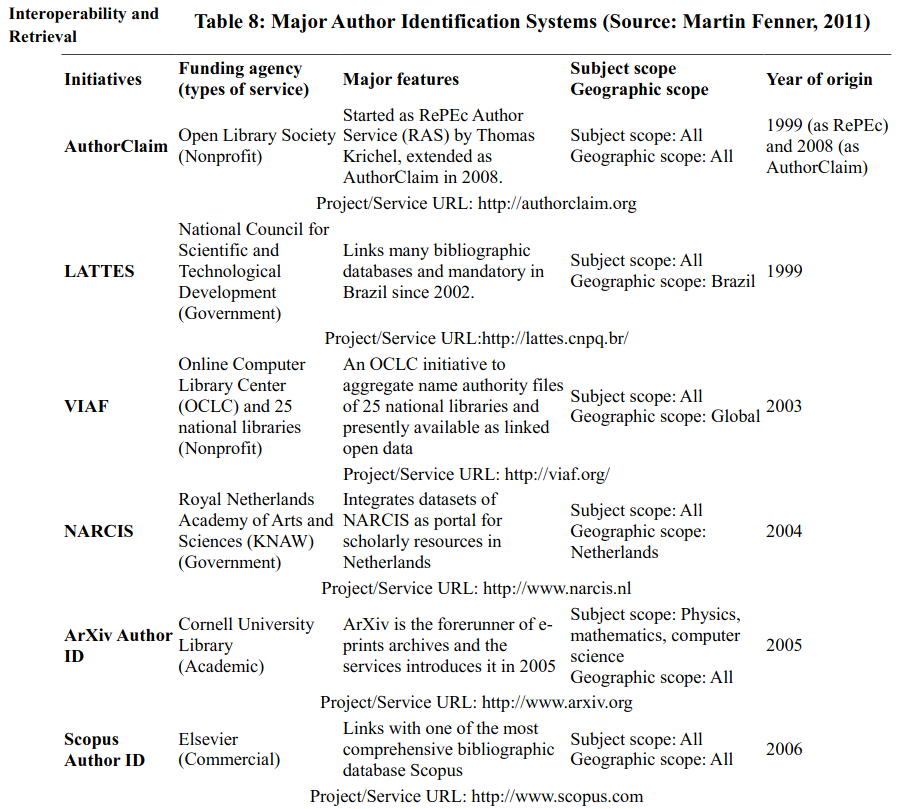
In the library world, VIAF (Virtual Internet Authority File) is coming as a comprehensive name authority service. It is an OCLC initiative to aggregate name authority data from 25 national libraries and the interesting fact is that the whole dataset is now available as Linked Open Data (LOD). It means these datasets can be linked dynamically with the DC.Creatormetadata field in different repository software. However, the major initiatives in the area of author identification are reported by Fenner (2011) and on the basis of that a report on chronological evolution of initiatives with relevant information is given in Table 8.

Object Identifiers
Digital ID is a necessary foundation of many forms of online exchange. Internet allocates a numeric identifier for host computers or servers, called IP address. Domain name system is textual representation of IP address. These two schemes uniquely identify servers (or any connected device) in the network. Apart from these interoperability standards for machines, standards like URL, URN, DOI CNRI handle, PersID, DataCite etc are in use to achieve interoperability in digital resource access and exchange. Interoperability requires persistent and actionable object names. The features of unique identifier for digital resources are (DOI79 Foundation):
- Object names require mechanisms for persistence;
- Object identification requires action-ability (it means resolution from a name to some service);
- Object representation requires specification of an object (it may be achieved either through simple referencing or more formal description); and
- Object naming requires standard syntax (demands prescriptive rules for assigning identifiers in a standard format ensuring uniformity and uniqueness). The major initiatives in unique object identification of scholarly resources are;
DOI (Digital Object Identifier) System
The International DOI Foundation developed a generic standard for unique identification of digital objects including scholarly digital resources. The features of the DOI system are as follows:
- The DOI System uses naming syntax on the basis of NISO standard Z39.84;
- DOI name persistence is guaranteed through social infrastructure which provides rules for registration, formal resilience procedures etc;
- The DOI System applies the Uniform Resource Name (URN) and the Uniform Resource Identifier (URI);
- URI and URN specifications in DOI deal only with syntax;
- Uniform Resource Identifier (URI) specification in DOI is based on IETF RFC 2396 standard;
- URN (Uniform Resource Name) specification in DOI is based on RFC 2141;
- DOI is Neutral as to implementation (the design of DOI is not specific to Web only and may work in non-Web environment);
- DOI allows granularity of naming and administration at the object level; and
- DOI is neutral as to language, script or character set (Unicode may represent DOI in any script).
Handle System
Handle system is an initiative of Corporation for National Research Initiatives (CNRI) to manage unique and persistent identification of digital resources in a heterogeneous network environment. The handle system is based on the Digital Object Architecture of CNRI. The architecture has following features:
- Allows identification, access and protection (if required);
- Machine and platform independent;
- Incorporates not only digital object but also unique identifier and associated metadata;
- Metadata may include rights related information, licensing agreement and restriction on access (if any);
- Handle includes namespace, open set of protocols and necessary reference implementation;
- Protocols enable to persistent identifiers of digital resources (known as handles) in a distributed computing system;
- Handles can be resolved into set of information that are necessary to locate, access and authenticate the digital resources;
- Information set can be changed and modified (to suite current state of the resources) without changing the identifier;
- Ensures persistent access to digital objects in spite of changes in location and other related status information;
- Handles allow identification of digital objects with a persistent URL (means handle can identify a digital object even the URL of the object itself changes);
- Repositories or other service providers need to register in CNRI handle (handle.net) system and implement handle at local level (see Figure 15 and Fig 16).
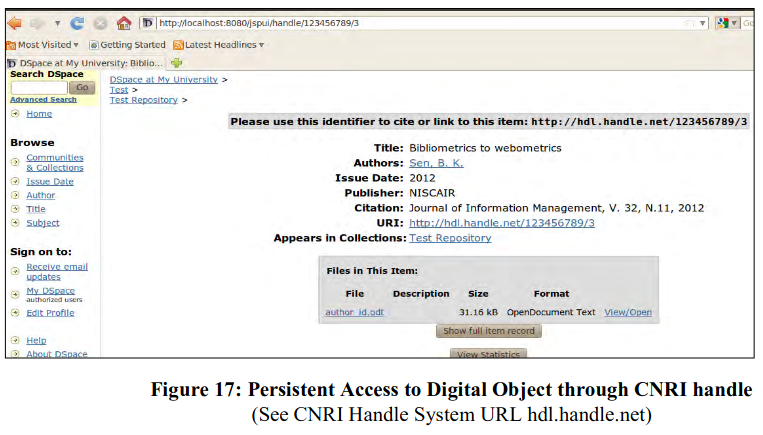
The Handle System has significant advantages in unique and persistent identification of digital objects: i) it is a global resolution service; ii) the plug-in is available freely and tested across multiple platforms/applications; iii) URN plug-ins may be configured to provide server-side support; iv) platform independent implementation; iv) available with added security features; v) can be delivered through web browser. DSpace, a globally reputed open source repository management software incorporated CNRI handle system right from the beginning. After registering and obtaining CNRI handle, administrator of DSpace can enter handle obtained in configuration file.

After submission of digital objects in repository by authors/submitters, a handle is allotted by the software according to the handle prefix (here 123456789 – a fictitious handle). For example (see Figure 16) after successful submission one digital objects received handle 123456789/3 with URL http://hdl.handle.net/123456789/3. The user interface also allows global unique and persistent access to digital object during retrieval irrespective of the URL of the repository (see Figure 17).
PersID
This unique identification system is a joint initiative of national libraries (National libraries of Sweden, Denmark, Germany), national research bodies (DANS, Netherlands; DEFF, Denmark; FDR, Italy, CNR, Italy) and some international projects (Knowledge Exchange, SURF Foundation). This identification system provides identifiers by combining URN (Uniform Resource Names) and NBN (National Bibliography Numbers) in the form of URN: NBN. It supports persistent identification of knowledge objects through an international infrastructure and knowledge base. URN is a specification of IETF (Internet Engineering Task Force), a W3C organ and bibliographic identification systems includes ISBN (a 13 digit number in the line of EAN –European Article Number), ISSN, ISMN etc. PersID80 may be applied to a wide range of web resources.
DataCite
DataCite81 is an international foundation working in the area of unique and persistent identification of published digital datasets since 2009. It is a membership based organization and is closely related to over hundred data centres all over the world. The founder members of DataCite include esteemed institutes like the British Library, Purdue University, National Library of Science and Technology, Germany, National research Council, Canada and many more. The partner data centres include California Digital Library, US; Australian National Data Service; Beijing Genomics Institute etc. The DataCite initiative has following features:
- Works in close liaison with data centres around the world-wide;
- Assigns persistent identifiers to datasets in consultation with data centres;
- Includes method for data citation, data discovery and dataset linking with related resources such as journal papers; Persistent identifiers will be assigned against membership registration;
- Citable datasets (as scholarly contribution) may create a new method for measuring scientific productivity;
- Promotes data arching for future use and re-purposing.
DataCite is a member of the International DOI Foundation. The members of DataCite support registration for DOIs. Some DataCite members provide registration facilities through their own APIs and others use DataCite API directly for registration (see Figure 18).

DataCite will be utilized in DSpace from version 4.0 onwards. DSpace is planning to use DataCite in two alternative ways – i) administration of DOIs by using the DataCite API directly; or ii) by using the API from EZID (a service of the University of California Digital Library, an active member of DataCite Initiative).
2.3.6 Object-level Interoperability Initiatives
Enhanced publications are rapidly becoming a trend of the scholarly communication process. Research publications are now increasingly attached with datasets, models, algorithms, images, streaming videos, post publication materials (like comments, blog posting, citations, ranking etc). Enhanced publications are compound digital objects that include text, audio, video, image etc. The concept of enhanced publications in OA domain was first reported by DRIVER project and developed further by another OA project SURF to integrate open data and publication. Exchange and sharing of compound digital objects or enhanced publication failed due to two reasons –i) there is no standard way to identify an aggregation; and ii) there is no standard way to describe the constituents or boundary of an aggregation. OAI-ORE, as an interoperability standard for compound digital objects, aims to provide solution that supports aggregations of Web resources. Open Archives Initiative (OAI) - Object Reuse and Exchange (ORE) is a standard developed by Open Archive Initiative under the leadership of Pete Johnston of Eduserv Foundation. OAI-ORE works on the basis of following principles:
Based on Web architecture with four basic components – i) Resource (an item of interest); ii) URI (a global resource identifier); iii) Representation (a data stream accessible through URI by using a protocol like HTTP ); and iv) Link (a connection between two resources);
- Supports Semantic web, Linked data and Cool URI;
- Provides XML-based serialization for the Resource Description Framework (RDF);
- Can unambiguously refer to an aggregation of Web resources through Aggregation URI (represents a set or collection of other Resources);
- Web Aggregation is also called Resource Map (provides machine-readable representation about the Aggregation and it has a URI);
- Resource Maps can be expressed in different formats including Atom XML, RDF/XML, RDFa, n3, turtle, and other RDF serialization formats;
- Resource Map is able to return an RDF/XML or Atom XML document against HTTP request and clients/agents can then interpret resource map to provide enhanced services like navigation, printing, archiving, visualizing, and transforming the Aggregation.
Almost all major open source repository management software like DSpace, Eprint and Fedora are supporting OAI-ORE for harvesting compound digital objects. Eprint archive repository management software allows both harvesting compound digital objects by using OAI-ORE and can also export items in OAI-ORE compatible format. OAI-ORE is presently in version 1.0 and it has all the capabilities to emerge as de facto global standard for the interoperability of aggregated digital resources. It follows a simple but robust ORE data model and compliant with Linked Open Data (LOD) and Semantic Web technologies.