3.5 Retrieval of Open Contents: Support Tools
As you know, language is a basic element of the Information Representation and Retrieval (IRR). It may take the form of either natural language or controlled vocabulary (a relatively latecomer in comparison to natural language). The applications and uses of languages in IRR may be studied under four groups, called four era of IRR language (Svenonious, 1986; Rowley, 1994; and Chu, 2009). The characteristics of these four eras may be summarized as below:


Digital IRR including OA retrieval system generally use controlled vocabulary for populating subject access fields (like DC.Subject) but the use of natural language is increasing with the improvement of Natural Language Processing (NLP) technologies. Application of NLP may broadly be categorized into three groups:
Group I: Use of terms taken from titles, topic sentences, abstracts, and other important components (Assigned indexing)
Group II: Use of terms that are derived from any part of the document (Derived indexing)
Group III: Use of words or phrases from query representation of searchers
Activities of these three groups, related with natural language based information representation, are associated with inclusion of significant or desired words (i.e. candidate terms for indexing or query) and exclusion of non-significant or junk words (such as articles, prepositions, conjunctions etc.). In an automatic IRR a stop-word list is compiled and configured in system to stop indexing of the junk words. Some automatic IRR systems create go-list or desired word list as semi-structured vocabulary, which includes significant terms (along with synonyms etc.) from established vocabulary control devices (like thesauri, subject headings list etc.).
3.5.1 Vocabulary Control Devices
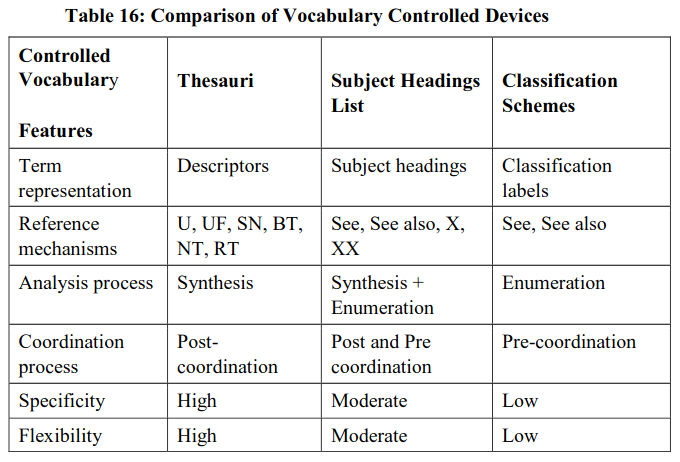
Controlled vocabularies are artificial languages with their own vocabulary, syntax and semantics. The vocabulary in a controlled vocabulary device is based on literary warrant and users warrant. Controlled vocabularies available in IRR domain may be divided into three groups – thesaurus, subject headings list, and classification scheme. As information professional you are already familiar with these devices. Therefore, a comparison of these devices may help you in determining their suitability for different applications (Table 16).
Natural language or Controlled vocabulary: Which Way?
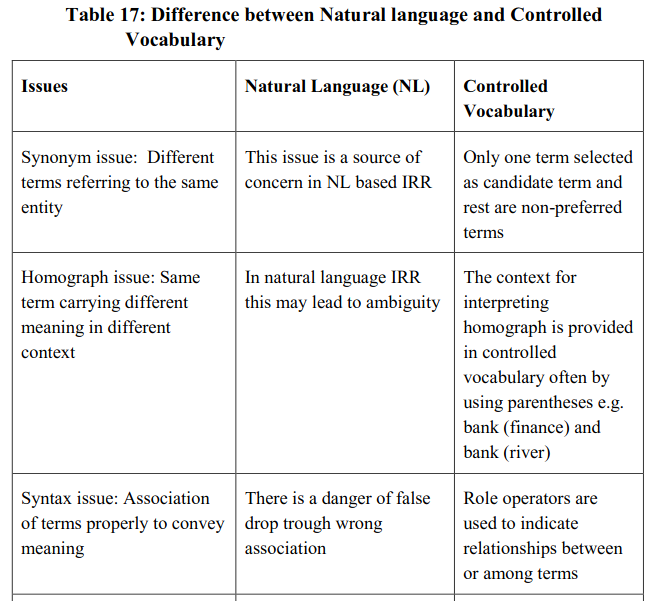
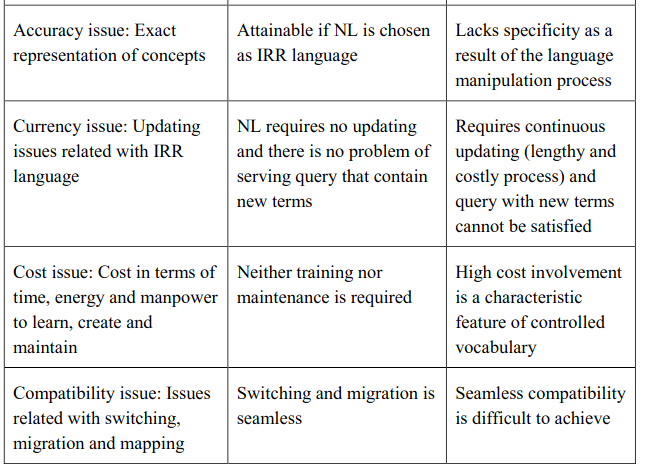
The four era of language in IRR (as described in foregoing paragraph) shows the trend of using natural language and controlled vocabulary in a combined way. Both of these groups have their own advantages and disadvantages. As a result, these two groups of language are applied in complimentary and supplementary basis for developing information retrieval system. A comparison of suitability for these two groups of language against major selected issues may be presented in Table 17.
As a whole we can conclude that advantages of using controlled vocabulary are related with efficient handling of synonyms, homographs and term association (syntax), and these are weak points of natural language. The advantages of using natural language are concerned with updating, accuracy, maintenance cost and compatibility, and these are weak points of controlled vocabulary. As a consequence of the relative merits of each of these systems, both have found their own places in IRR. The next sections shows you the use of controlled vocabularies in OA retrieval systems at two levels – use of controlled vocabulary for populating subject access fields and use of ontology in retrieval.
3.5.2 Subject Access Systems
There are broadly three parallel IR systems. These are traditional or manual IRR, online and optical disk based IRR, and Web-enabled IRR. In the first two IR systems, controlled vocabulary has taken a dominant role as IRR language. But in Web-enabled IRR, application of controlled vocabulary is a costly option in view of the ever increasing magnitude of digital resources coupled with the factors like uneven quality and short life expectancy for these resources. Most of the Web-enabled retrieval systems make no use of controlled vocabulary apart from stop-lists or go-lists. The lack of controlled vocabulary as IRR language could be one of the reasons for non-satisfactory performance of these retrieval systems. Under such circumstances one question is gaining serious attention from library professionals –what will be the future of controlled vocabulary as a language in digital IRR. Lancaster & Warner (1993) advocated four possible approaches in this direction:
Solution I: Controlled vocabulary for both representation and retrieval
Solution II: Natural language for both representation and retrieval (by using role operators and pre-coordination processes from controlled vocabulary)
Solution III: Controlled vocabulary for representation only (use of invisible vocabulary control device at the back-end of the retrieval system)
Solution IV: Controlled vocabulary for retrieval only (use of vocabulary control device at the front-end of the retrieval system i.e. in search interface)
The last three approaches are equally viable in digital IRR environment as far as cost of creation and maintenance of the IR systems is concerned. But the third and fourth approaches require settling the issues related with switching and mapping of vocabularies. A comparison of these two mechanisms gives us following result:
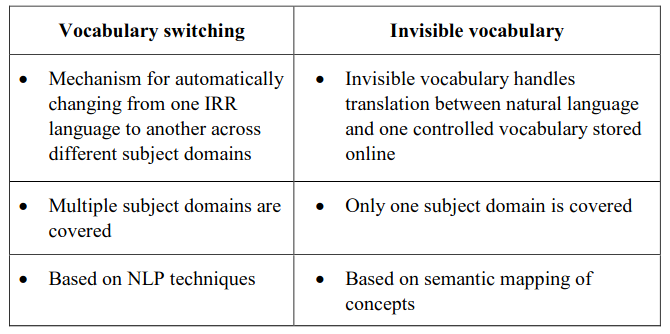
Digital repository software are increasingly aware of the advantages of using controlled vocabularies in retrieval particularly in populating subject access fields. The Eprint archive software right from the beginning using standard subject access system (by default LC Subject categories but it may be configured to include any such subject categorization) for at the time indexing as well as at the time of searching. Figure 37 shows the use of standard subject access system at time of submitting open knowledge objects.
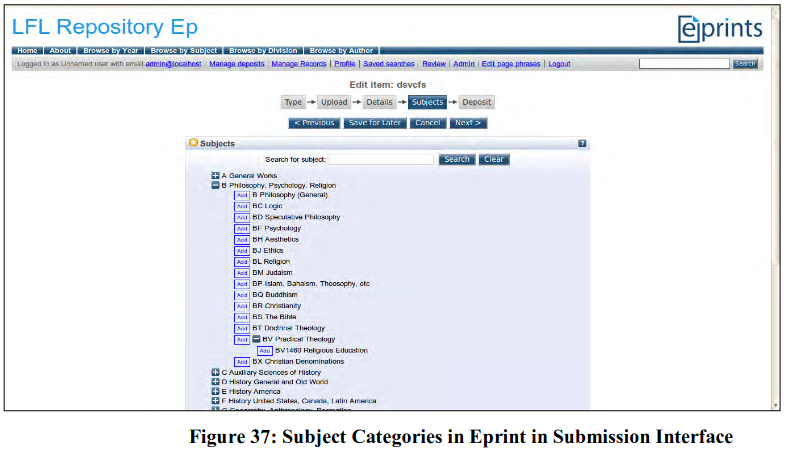
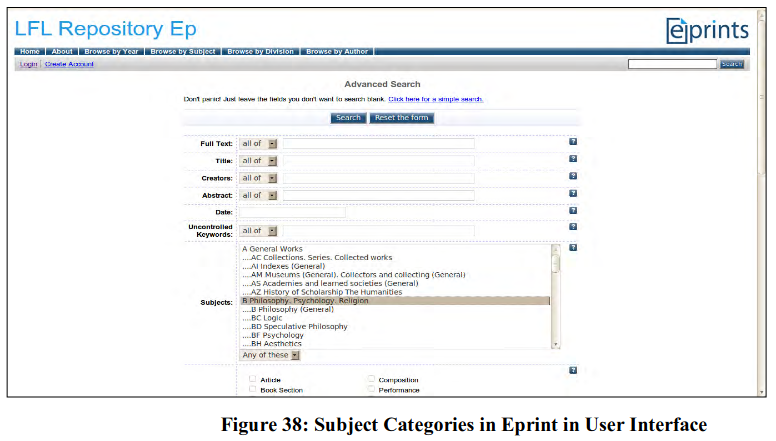
After submission process is over, the subject field is populated by selected subject category or subcategory and it becomes ready for searching by subject category in indexing process (see Figure 38).
DSpace also supports the use of controlled vocabularies in indexing and searching but the process of integration is much more flexible. It supports SKOS (Simple Knowledge Organization System), a W3C recommendation, for representing and formatting subject hierarchy. As a result, integration of subject categorization in DSpace and interoperability of subject categories from/to DSpace is standardized.
Step 1: Enabling Controlled vocabulary
It involves opening controlled vocabulary option in dspace.cfg file
Step 2: Creating SKOS-enabled Subject Access System
This step involves representation of subject access system in SKOS format in XML. This XML based representation of subject hierarchy also provides scope for inclusion of multilingual subject heading. It means subject heading / preferred term may be represented in more than one language or scripts.
Step 3: Linking Submission interface with Subject Access System
This step links the XML-formatted standard subject access system with submission interface (for indexing).
These three steps integrate controlled vocabularies in DSpace for managing retrieval of open contents in both interfaces – indexing phase and end user searching phase.
3.5.3 Ontology Support
Ontology is a formal, explicit specification of a shared conceptualization. In simple words, it is a model of organized knowledge in a given domain (e.g. fisheries). Ontologies consist of components called “concepts, attributes, relations and instances”. Ontology is considerably different from taxonomy and thesaurus. Taxonomy is a hierarchical tree structure which models a domain from abstract to specific. On the other hand a thesaurus is a structured vocabulary that defines each term by three major types of relationships –hierarchical (as in a taxonomy), associative and equivalent. But ontology is the most formal model as it defines the meaning of concepts by modeling constraints that restrict the number of possible interpretation. Therefore, these three schemes differ mainly in their degree of precision. However, a comparison is given here in Table 18 to help you in understanding the features.
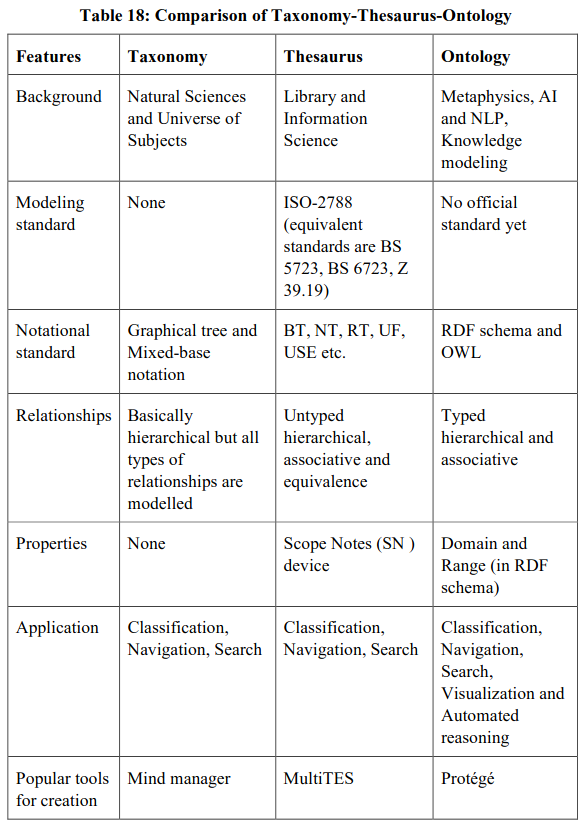
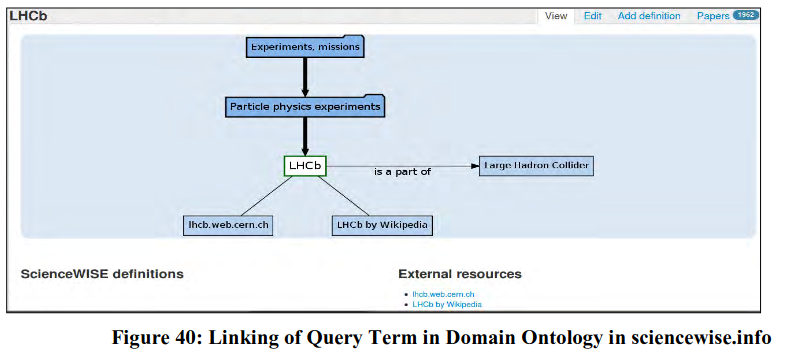
Thesauri are structured according to an international standard (ISO-2788), and, therefore, these schemes can be transferred to ontologies through the application of ontology representation language (such as RDF schema). In Semantic Web environment, we need an element which can unequivocally describe the meaning of a concept or word for the software agent. This role is performed by ontologies. In practice, desired words/concepts/terms are marked by a tag that refers to the ontology. A software agent who comes across the tag can consult the ontology for meaning of the term. The Semantic Webextends the present form of Web by giving meaning and context to information bearing objects, allowing people and software agents to share and process data more competently. Ontology helps to boost the effectiveness and uniformity of describing resources i.e. they allow more sophisticated functionalities in IRR. The use of standards, such as the Resource Description Framework (RDF) and Web Ontology Language (OWL), provide structures and methods for descriptions, definitions and relations within a given domain. In OA domain, some of the content retrieval systems support ontology-driven retrieval of knowledge objects. For example, sciencewise.info an experimental OA retrieval system (presently covers Physics, Life Sciences, Humanities and Information Technologies disciplines) provides ontology-driven search interface. A search query is automatically linked with available domain ontology and user allows navigating from one Node to another. It also gives users links to open contents (preprints/post prints).
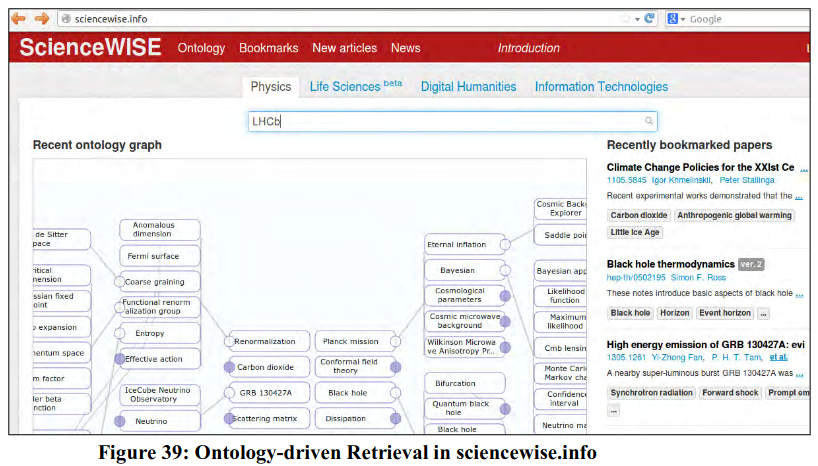
For example, a search on LHCb in sciencewise.info shows position of the query term in domain ontology (including it’s relationships with other concepts) and provides link to available open access journal papers related to LHCb (Figure 39 & 40). This is also a participative retrieval architecture which allows user scope to define a new concept or to edit an existing concept in domain ontology.
3.5.4 Statistical and Other Tools
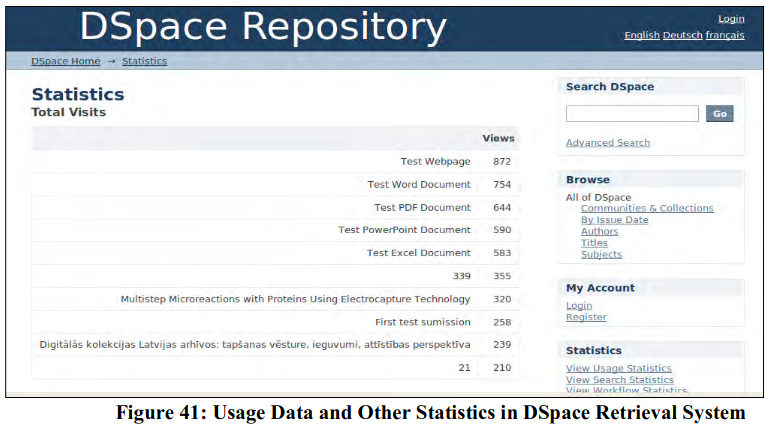
You already know in Unit 2 of this Module that usage data and statistics is considered as a value-added feature for any OA retrieval system. Many repository software are attempting to implement the statistics add-on by using usage data stored in retrieval engine. For example, the statistics add-on in the DSpace platform allows gathering, processing and presenting usage data, contents related data and administrative statistics by utilizing Apache Solr (text retrieval engine in use in DSpace version 4.0) underlying application layer for harvesting vast array of usage data. Some of the statistical datasets displayed by DSpace are – top ten countries and cities from where visits originate, total number of visits for community, collection and items, search history, work-flow related statistics, item download statistics etc (Figure 41).
The other associated services that support OA retrieval system are Web 2.0 tools for achieving interactive, collaborative and participative architecture in content retrieval. These are use of RSS feeds, content rating, folksonomy, review submission, social networking tools etc. Shafi, Gul and Shah (2012) conducted a study in 2012 to measure the use of Web 2.0 tools and services in OA repositories listed in openDOAR (1977 to be exact). The finding of this research provides shows that the use of RSS is the most popular Web 2.0 application in OA retrieval (possibly the use of RSS as automatic alerting service for updated contents makes it very useful support tool in OA retrieval) and social bookmarking occupies the next position (again because of scholarly reasons). The other useful Web 2.0 tools are social networking tools (Twitter, Face book, and YouTube) and collaborative tools (like Blog, Flickr, and Podcasting). In a total of 1,412 accessible repositories (in 1977 total listed repositories), 57 percent (804 number of repositories) applied Web 2.0 tools and the remaining 43 percent (608 number of repositories) have not yet applied Web 2.0 tools. Again a country-wise distribution of the use of Web 2.0 tools in OA repositories shows that US based OA retrieval systems ranked first and UK and Germany occupied the next positions respectively. One interesting fact is that use of web 2.0 tools in Asian OA retrieval systems are increasing (Taiwan – 83.33%, India – 60% and Japan – 41.56%) in comparison with European and American OA retrieval systems.